

Today, most companies understand the significant benefits of the “Age of Data.” Fortunately, an ecosystem of technologies has sprouted up to help them take advantage of these new opportunities. But for many companies, building a comprehensive modern data ecosystem to deliver data value from the available offerings can be very confusing and challenging. Ironically, some technologies that have made specific segments easier and faster have made data governance and protection appear more complex.
Big Data and the Modern Data Ecosystem
“Use data to make decisions? What a wild concept!” This thought was common in the 2000s. Unfortunately, IT groups didn’t understand the value of data – they treated it like money in the bank. They thought data would gain value when stored in a database. So they prevented people from using it, especially in its granular form. But there is no compound interest on data that is locked up. The food in your freezer is a better analogy. It’s in your best interest to use it. Otherwise, the food will go bad. Data is the same – you must use, update, and refresh it, or else it loses value.
Over the past several years, we’ve better understood how to maximize data’s value. With this have come a modern data ecosystem with disruptive technologies enabling and speeding up the process, simplifying complicated tasks and reducing the cost and complexity required to complete tasks.
But looking at the entire modern data ecosystem, it isn’t easy to make sense of it all. For example, suppose you try to organize companies into a technology stack. In that case, it’s more like “52 card pickup” – no two cards will fall precisely on each other because very few companies present the same offering and very few cards line up side-to-side to offer perfectly complementary technologies. This is one of the biggest challenges of trying to integrate best-of-breed offerings. The integration is challenging, and interstitial spots are difficult to manage.
If we look at Matt Turck’s data ecosystem diagrams from 2012 to 2020, we will see a noticeable trend of increasing complexity – both in the number of companies and categorization. It isn’t evident even for those of us in the industry. While the organization is done well, pursuing a taxonomy of the analytics industry is not productive. Some technologies are mis-categorized or misrepresented, and some companies should be listed in multiple spots. Unsurprisingly, companies attempting to build their modern stack might be at a loss. No one knows or understands the entire data ecosystem because it’s massive. These diagrams have value as a loosely organized catalog but should be taken with a grain of salt.
A Saner, but Still Legacy Approach to the Modern Data Ecosystem
Another way to look at the data ecosystem—one that’s based more on the data lifecycle is the “unified data infrastructure architecture,” developed by Andreessen Horowitz (a16z). The data ecosystem starts with data sources on the left, ingestion/transformation, storage, historical processing, and predictive processing and on the right is output. At the bottom are data quality, performance, and governance functions pervasive throughout the stack. This model is similar to the linear pipeline architectures of legacy systems.
Like the previous model, many of today’s modern data companies don’t fit neatly into a single section. Instead, most companies span two adjacent spaces; others will surround”storage,” for example, having ETL and visualization capabilities, to give a discontinuous value proposition.
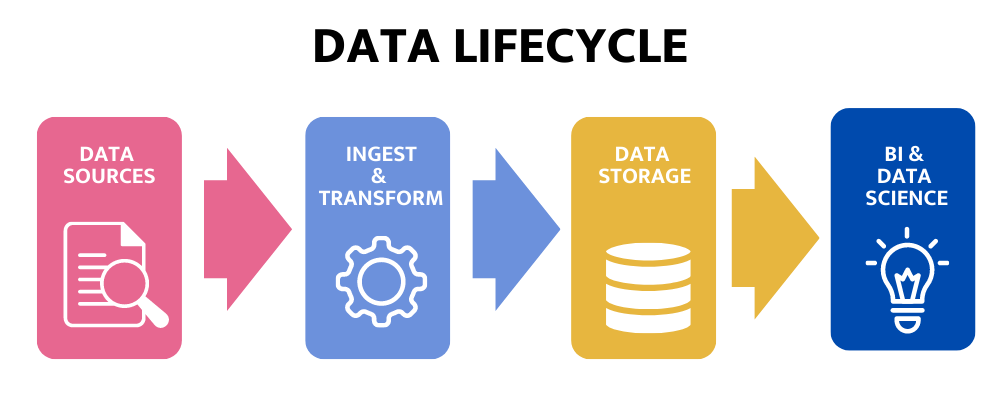
1) Data Sources
On the left side of the modern data ecosystem, data sources are obvious but worth discussing in detail. They are the transactional databases, applications, application data and other datasources mentioned in Big Data infographics and presentations over the past decade. The main takeaway is the three V’s of Big Data: Volume, Velocity and Variety. Those Big Data factors had a meaningful impact on the Modern Data Ecosystem because traditional platforms could not handle all V’s. Within a given enterprise, data sources are constantly evolving.
2) Ingestion and transformation
Ingestion and transformation are a bit more convoluted. You can break this down into traditional ETL or newer ELT platforms, programming languages for the promise of ultimate flexibility, and event and real-time data streaming. The ETL/ELT space has seen innovation driven by the need to handle semi-structured and JSON data without losing transformations. There are many solutions in this area today because of the variety of data and use cases. Solutions are capitalizing on the ease of use, efficiency, or flexibility, where I would argue you cannot get all three in a single tool. Because data sources are dynamic, ingestion and transformation technologies must follow suit.
3) Data Storage
Storage has recently been a center of innovation in the modern data ecosystem due to the need to meet capacity requirements. Traditionally, databases were designed with computing and storage tightly coupled. As a result, the entire system would have to come down if any upgrades were required, and managing capacity was difficult and expensive. Today innovations are quickly stemming from new cloud-based data warehouses like Snowflake, which has separated compute from storage to allow for improved elasticity and scalability. Snowflake is an interesting and challenging case to categorize. It is a data warehouse, but its Data Marketplace can also be a data source. Furthermore, Snowflake is becoming a transformation engine as ELT gains traction and Snowpark gains capabilities.While there are many solutions in the EDW, data lake, and data lakehouse industries, the critical disruptions are cheap infinite storage and elastic and flexible compute capabilities.
4) Business Intelligence and Data Science
The a16z model breaks down into the Historical, Predictive and Output categories. In my opinion, many software companies in this area occupy multiple categories, if not all three, making these groupings only academic. Challenged to develop abetter way to make sense of an incredibly dynamic industry, I gave up and over simplified. I reduced this to database clients and focused on just two types: Business Intelligence (BI) and Data Science. You can consider BI the historical category, Data Science the predictive category and pretend that each has built-in “Output.” Both have created challenges to the data governance space with their ease of use and pervasiveness.
BI has also come along way in the past 15 years. Legacy BI platforms required extensive data modeling and semantic layers to harmonize how the data was viewed and overcome slower OLAP databases’ performance issues. Since a few people centrally managed these old platforms, the data was easier to control. In addition, users only had access to aggregated data that was updated infrequently. As a result, the analyses provided in those days were far less sensitive than today. In the modern data ecosystem, BI brought a sea of change. The average office worker can create analyses and reports, the data is more granular (when was the last time you hit an OLAP cube?), and the information is approaching real-time. It is now commonplace for a data-savvy enterprise to get reports updated every 15 minutes. Today, teams across the enterprise can see their performance metrics on current data and enable fast changes in behavior and effectiveness.
While Data Science has been around for a long time, the idea of democratizing has started to gain traction over the past few years. I use the DS term in a general sense of statistical and mathematical methods focusing on complex prediction and classification beyond basic rules-based calculations. These new platforms increased the accessibility of analyzing data in more sophisticated ways without worrying about standing up the compute infrastructure or coding complexity. “Citizen data scientists” (using this term in the most general terms possible) are people who know their domain, have a foundational understanding of what data science algorithms can do, but lack the time, skill, or inclination to deal with the coding and the infrastructure. Unfortunately, this movement also increased the risk of exposure to sensitive data. For example, analysis of PII may be necessary to predict consumer churn, lifetime value or detailed customer segmentation. Still, I argue it doesn’t have to be analyzed in raw or plain text form.
Data tokenization—which allows for modeling while keeping data secure—can reduce that risk. For example, users don’t need to know who the people are and how to group them to execute cluster analysis without needing exposure to sensitive granular data. Furthermore, utilizing a deterministic tokenization technology, the tokens are predictable yet undecipherable to enable database joins if the sensitive fields are used as keys.
Call it digital transformation, the democratization of data or self-service analytics, the aesthetic for Historical, Predictive, Output – or BI and Data Science – is making the modern data ecosystem more approachable for the domain experts in the business. This also dramatically reduces the reliance on IT outside of the storage tier. However, the dynamics of what data can do requires users to iterate, and iterating is painful when multiple teams, processes, and technology get in the way.
Modern Data Ecosystem Today: a Lighter Lift leads to Other Issues
When looking back at where we came from before the Modern Data Ecosystem, it seems like a different world. Getting data and making sense of it was a heavy lift. Because it was so hard, there was an incentive to “do it once” driving large scale projects with intense requirements and specifications. Today the lift is significantly lighter – customers call it quick wins; vendors call it land and expand. Ease of use and User Experience have become table stakes where the business user is now empowered to make their own data-driven decisions.
But despite all the innovations by the enterprise software industry, there are some areas that have been left behind. Like a car that got an upgrade to its engine but still has its original steering and wheels, the partially increased performance created increased risk.
The production data & analytics pipeline that will remain unchanged for years is dead. Not only that, but there is also no universal data pipeline either. Flexible, easy to create data pipelines and analytics are key to business success.
All the progress over the past decade or so has left some issues in its wake:
A single, stable, and linear data pipeline is dead
I once heard from a friend of mine who is a doctor that said, “If there are many therapies for a single ailment, chances are none of the therapies are good”. I used to draw a parallel of that adage to data pipelines, but I realized that the analogy falls short. It falls short since there are many data pipeline problems that need to be solved with their own needs. Data pipelines can be provisional or production, speedy or slow, structured or unstructured. The problem space where data ingestion and pipelines live is massive to the point where having a purposeful choice is the best play. Taking the 52-card pickup reference from earlier – you need a good hand to play with and in this game, you can choose your own cards.
Lift and shift to the cloud can exacerbate as many problems as it solves
One of the methods of enterprise architecture modernization is obviously moving to the cloud. Taking server by server, workload by workload and moving it to the cloud aka “lift and shift” has seemed to be the fastest and most efficient way to get to the cloud. And I would agree that it does but can inhibit progress if done in a strict mechanical way. Looking back at the data ecosystem models, new analytics companies are solving problems in many ways. So, the lift and shift method has a weakness that can cause one of two problems. Taking the old on-prem application and porting it to the cloud prevents any infrastructural advantages the cloud has to offer (scale and elasticity is the most common one). It also inhibits any improvements from a functional architecture perspective. It could be performing calculations in the BI or Data Science layer where it could perform better or be more flexible elsewhere. The one we will focus on later is governance from an authorization or protection point of view.
Governance needs to move away from the application layer
I touched on this in the last paragraph but deserves to be called out on its own. Traditionally data governance was a last mile issue. Determining who had the correct privileges to see a report or an analysis was executed when it was minted. In my opinion this is a throwback from the printed report era because you were literally delivering the report to an in box or an admin which can have its own inherent governance. The exact processes don’t follow through, but the expectations did. This bore an era of creating software where rudimentary controls were deployed at the database, but the sophisticated controls were in the application. Fast forward back to the present day. Analytics and reporting are closer to a BYOD cell phone strategy than a monolithic single platform for reports. This creates an artificial zero-sum game where analytic choice is at odds with governance. The reality is companies need to be analytically nimble to stay competitive. Knowledge workers want to support their company to stay competitive and will do whatever they can to do so. The culmination of easy-to-use software that is impactful allows users to follow the path of least resistance to get their job done.
How the Modern Data Ecosystem Broke Traditional Governance
While pockets of the data ecosystem have been advancing quickly, data governance has fallen behind when it comes to true innovation. With traditional software, governance was easy because everything else was hard: the data changed slowly, the output was static. The teams executing all this technology were small, highly trained, and usually located in a single office. They had to be because the processes were hard and confusing, and the technology was very difficult to implement and use. The side effect was that data governance was easier to do because data moved slower, was in fewer places and fewer people had access. The modern data ecosystem eliminated each of these challenges one by one. Governance became the legacy process and technology that couldn’t keep up with the speed of modern data.
Does governance need to be hard or partially effective? I would argue not, if you apply it at the right part of the process: the data layer. Determining risk exposure is important. That is where the analytics metadata management platforms have done so well. The modern data ecosystem enabled the creation of a wealth of data, analytics, and content. Management from a governance perspective provides a view into where the high-risk content is. Now we need an easy-to-use platform to execute on a governance strategy.