

With data breaches heating up worldwide, protecting your data is more important now than ever. It is critical to have your sensitive data protected not only in your data warehouse but at every stage of your data pipeline. Specifically, if you have object tags in Snowflake, this is a great solution to apply masking policies to protect data, but it is only good if these tags are upheld in your data pipeline. There are several solutions available, with the newly released contracts and constraints standing out as particularly effective. Let’s dive in and discover how these innovations can enhance your data management strategies.
DBT
If you’re unfamiliar with dbt, let’s provide some context. It is important to note that dbt is not classified as an ETL tool; rather, it is designed for transforming data using SQL. So, once you extract and load your data into your preferred data warehouse, you can then transform that data by utilizing dbt. By transforming your data, you can integrate, organize, filter, and aggregate it, allowing you to gain value and insights from it. It supports many data warehouses and focuses on bringing software engineering practices to data (modularity, code sharing, documentation, ci/cd, etc). If you know SQL, with dbt you can build production-grade data pipelines.
DBT Problem
As mentioned, SFOTs are an excellent way to protect sensitive data by tagging columns, and then being able to apply SQL code by tags to protect those columns dynamically. If you are not keen on writing SQL for security, ALTR is a progressive product that offers the ability to easily and conveniently apply dynamic data masking to tags based on role and what level of access, no matter if you know SQL or not. Anyone can apply policy on data with ease. However, when you begin to integrate other tools into your pipeline where security isn’t a primary focus, the integrity of your data protection becomes increasingly uncertain. In particular, a downside to dbt is when it is run, it recreates objects. This process results in the loss of tags, which can lead to the removal of masking policies and expose personal data.
DBT Solutions
There are a few solutions to being able to utilize SFOT with dbt. In particular, number 4 is at the forefront of solutions and was just released, fixing the problem with the most functionality. I’ll dive into each briefly. Please note those with a ‘*’ is not a feasible solution for sensitive data.
You can…
1. Avoid dbt materializations that recreate objects.
- Incremental tables: only create a table on the first run and add to it after. Downsides- limits functionality and you still have to manually apply tags after the first run
- Only create views: if the underlying tables have SFOTs with masking policies, then the views will be protected. Downsides- limits functionality (no joins)
2. *Opensource DBT util package: a macro that can turn dbt meta tags into SFOT. Downsides- NOT immediate, it is executed on-run-end = tables exposed for a short time
3. *ALTER TABLE in post hook: Downsides- Since each DDL statement in Snowflake executes as a separate transaction, there is a small window of time from CTAS and ALTER TABLE command where the data is not masked. Also, if the alter table command fails then the data would remain unmasked.
4. Contracts and Constraints: This is where I think dbt puts the icing on the cake, so to speak. With this solution, you can enforce tags on columns before the data ever reaches Snowflake, keeping data protected in your pipeline.
- Contracts: You define a set of ‘guarantees’ and the dbt model will not be built if the model’s transformation’s dataset does not match the guarantees. In other words, under ‘contract’, the data model must contain the specified columns with the correct specified data types and constraints, or it won’t be built. Downsides: As of now, dbt contracts apply to all columns defined in a model, so you need to specify every column in the contract. This is an intent of the product, but dbt is currently investigating other options around this, as models with a lot of columns could mean a lot of yaml. However, I don’t view this feature as a downside, as it ensures, as a data engineer, you know exactly what you are producing.
- Constraints: These are the ‘guarantees’ you want to see in your data. Downside: support varies across platforms; can’t be applied on ephemeral models or materialized views.
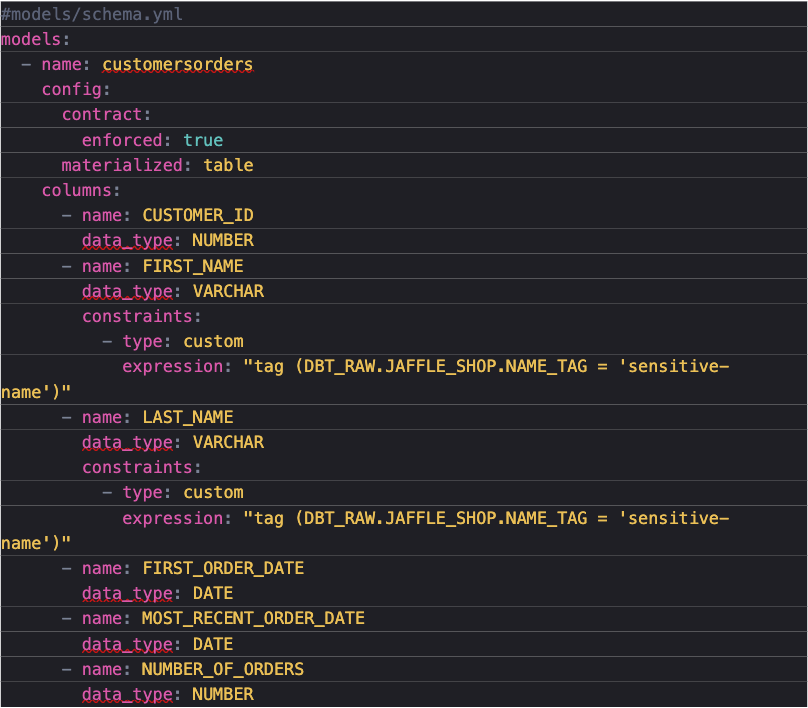
As seen in the code snippet above, I can apply the SFOT ‘name_tag’ to the first_name and last_name columns on the new table that is going to be built by this model. I set contracts to enforce, so by contract, if anything from customer_id not being data type ‘number’ to last_name not having had the SFOT, then the model will not be built. Although this could mean a lot of yaml for models with lots of columns, I think this is a premier solution to ensuring the safety of your data throughout your pipeline.
Wrapping Up
Since dbt recreates objects on ‘dbt run’, there are a few ways to get your SFOTs applied to the datasets dbt creates. The superior option is their newly released v1.5, contracts and constraints. Data plays an instrumental role in organizations, and as the amount of data inevitably increases, so does the need to ensure the right people have the right level of access. Whether it’s leveraging contracts and constraints with dbt or using ALTR to easily apply masking policies, have peace of mind around the security of your data at EVERY stage of your pipeline.