Data Classification
Classify Sensitive Data With Precision
ALTR’s Native Data Classification gives security teams full control over how sensitive data like PII, PHI and PCI is identified—accurately, consistently, and without compromise across modern cloud environments.
Designed for Accuracy, Control, and Scale
Eliminate Unknown Sensitive Data
Know where sensitive data actually lives and replace assumptions with verified discovery across environments.
Shift from Reactive to Proactive
Identify sensitive data before incidents occur and reduce surprise exposure during audits or investigations.
Trust Your Classification Results
Rely on classification results your team understands and base decisions on logic you control, not vendor black boxes.
Preserve Data Residency & Privacy
Classify data without exporting it externally and meet internal and regulatory expectations with confidence.
Scale Discovery Without Drag
Classify large datasets efficiently and predictably and avoid performance tradeoffs as data volumes grow.
Create Governance Consistency
Establish consistent, repeatable classification results and enable confident tagging and downstream policy decisions.
Key Features
Cloud Native Data Classification
Classify sensitive data entirely inside your cloud environment. No data movement, no external exposure, no third-party scanners.
Custom Sensitive Data Detection
Define sensitive data using specific patterns and criteria. Identify proprietary, regulated, and business-critical data with precision.
Predefined Classification Templates
Start quickly with predefined classifiers maintained by ALTR. Accelerate discovery while aligning to common regulatory data types.
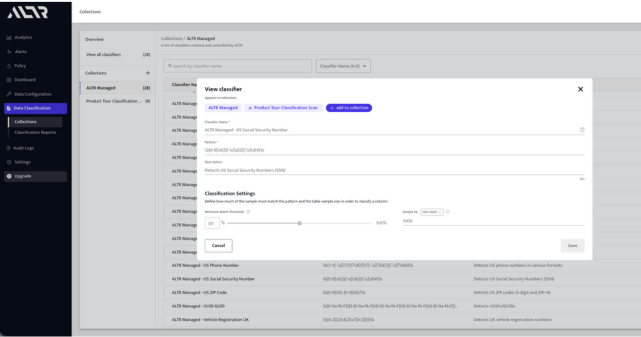
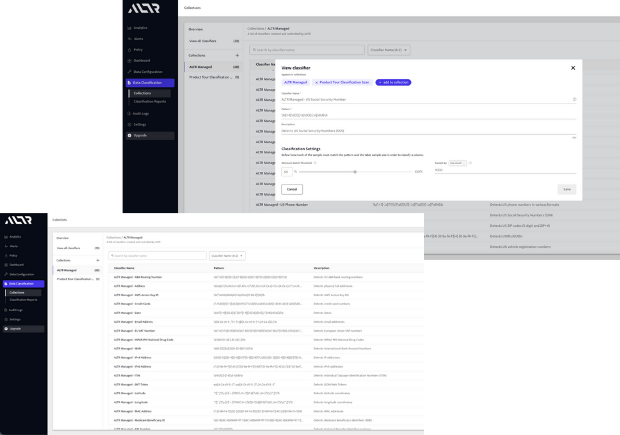
Threshold-Driven Classification Accuracy
Set minimum match thresholds to determine sensitivity. Reduce false positives and increase confidence in classification results.
Flexible Sampling for Any Data Scale
Scan by fixed row count or percentage of total data. Balance performance and accuracy across datasets of any size.
Reusable Classification Collections
Group classifiers into reusable collections for targeted scans. Run consistent, repeatable classification across data sources and teams.
Flexible Classification Methods. One Control Plane
ALTR Native Classification is the default for precision and security-owned discovery. For teams leveraging existing platform capabilities, ALTR also supports classification using Google DLP and Snowflake, so discovery fits your environment, not the other way around.
ALTR Native Classification
Security-owned, customizable classification designed for accuracy, control, and consistency across modern cloud data environments.
Google DLP Classification
Standardized, regulation-focused discovery for teams leveraging Google DLP on supported platforms.
Snowflake Native Classification
Native Snowflake-based classification for organizations looking to extend existing Snowflake investments.
Resources You Might Like



Frequently asked questions
What is ALTR Native Data Classification?
ALTR Native Classification is a security-owned approach to identifying sensitive data using custom and predefined classifiers that run directly within your cloud environment. It allows security teams to accurately discover sensitive data without relying on external scanning services.
How is ALTR's Native Data Classification different from Google DLP or Snowflake classification?
ALTR’s Native Data Classification gives security teams direct control over how sensitive data is identified, including custom detection logic, thresholds, and sampling. Google DLP and Snowflake classification rely on predefined vendor logic, while ALTR Native enables more precise, organization-specific discovery.
Does ALTR move or export my data during classification?
No. ALTR Native Data Classification scans data without exporting it to external services. Classification runs within your cloud environment, helping teams meet data residency, privacy, and regulatory requirements.
What types of data can ALTR classify?
ALTR Native Classification is designed for structured data such as tables and columns within modern cloud data platforms. It identifies regulated, sensitive, and business-critical data based on defined patterns and criteria.
Can security teams customize how sensitive data is detected?
Yes. Security teams can define organization-specific classification logic to reflect proprietary identifiers, internal formats, and regulatory requirements, rather than relying solely on generic templates.
How does ALTR handle large datasets during classification?
ALTR Native Classification supports flexible sampling strategies, allowing teams to scan data by fixed row count or by percentage. This enables efficient and accurate classification across datasets of any size.
Are data classification results reusable?
Yes. Classification logic can be grouped into reusable collections, allowing teams to run consistent, repeatable scans across multiple data sources without redefining detection rules each time.
Can ALTR support multiple classification methods?
Yes. While ALTR Native Classification is the default for precision and control, ALTR also supports Google DLP and Snowflake classification for teams leveraging existing platform capabilities.
How quickly can teams get started?
Teams can start immediately using ALTR-managed classification templates and expand to custom detection logic as needed. No extensive setup or data movement is required.