Format-Preserving Encryption: A Deep Dive into FF3-1 Encryption Algorithm
ALTR’s Format-Preserving Encryption, powered by FF3-1 algorithm and ALTR’s trusted policies, offers a comprehensive solution for securing sensitive data.
In the ever-evolving landscape of data security, protecting sensitive information while maintaining its usability is crucial. ALTR’s Format Preserving Encryption (FPE) is an industry disrupting solution designed to address this need. FPE ensures that encrypted data retains the same format as the original plaintext, which is vital for maintaining compatibility with existing systems and applications. This post explores ALTR's FPE, the technical details of the FF3-1 encryption algorithm, and the benefits and challenges associated with using padding in FPE.
What is Format Preserving Encryption?
Format Preserving Encryption is a cryptographic technique that encrypts data while preserving its original format. This means that if the plaintext data is a 16-digit credit card number, the ciphertext will also be a 16-digit number. This property is essential for systems where data format consistency is critical, such as databases, legacy applications, and regulatory compliance scenarios.
Technical Overview of the FF3-1 Encryption Algorithm
The FF3-1 encryption algorithm is a format-preserving encryption method that follows the guidelines established by the National Institute of Standards and Technology (NIST). It is part of the NIST Special Publication 800-38G and is a variant of the Feistel network, which is widely used in various cryptographic applications. Here’s a technical breakdown of how FF3-1 works:
Structure of FF3-1
1. Feistel Network: FF3-1 is based on a Feistel network, a symmetric structure used in many block cipher designs. A Feistel network divides the plaintext into two halves and processes them through multiple rounds of encryption, using a subkey derived from the main key in each round.
2. Rounds: FF3-1 typically uses 8 rounds of encryption, where each round applies a round function to one half of the data and then combines it with the other half using an XOR operation. This process is repeated, alternating between the halves.
3. Key Scheduling: FF3-1 uses a key scheduling algorithm to generate a series of subkeys from the main encryption key. These subkeys are used in each round of the Feistel network to ensure security.
4. Tweakable Block Cipher: FF3-1 includes a tweakable block cipher mechanism, where a tweak (an additional input parameter) is used along with the key to add an extra layer of security. This makes it resistant to certain types of cryptographic attacks.
5. Format Preservation: The algorithm ensures that the ciphertext retains the same format as the plaintext. For example, if the input is a numeric string like a phone number, the output will also be a numeric string of the same length, also appearing like a phone number.
How FF3-1 Works
1. Initialization: The plaintext is divided into two halves, and an initial tweak is applied. The tweak is often derived from additional data, such as the position of the data within a larger dataset, to ensure uniqueness.
2. Round Function: In each round, the round function takes one half of the data and a subkey as inputs. The round function typically includes modular addition, bitwise operations, and table lookups to produce a pseudorandom output.
3. Combining Halves: The output of the round function is XORed with the other half of the data. The halves are then swapped, and the process repeats for the specified number of rounds.
4. Finalization: After the final round, the halves are recombined to form the final ciphertext, which maintains the same format as the original plaintext.
Benefits of Format Preserving Encryption
Implementing FPE provides numerous benefits to organizations:
1. Compatibility with Existing Systems: Since FPE maintains the original data format, it can be integrated into existing systems without requiring significant changes. This reduces the risk of errors and system disruptions.
2. Improved Performance: FPE algorithms like FF3-1 are designed to be efficient, ensuring minimal impact on system performance. This is crucial for applications where speed and responsiveness are critical.
3. Simplified Data Migration: FPE allows for the secure migration of data between systems while preserving its format, simplifying the process and ensuring compatibility and functionality.
4. Enhanced Data Security: By encrypting sensitive data, FPE protects it from unauthorized access, reducing the risk of data breaches and ensuring compliance with data protection regulations.
5. Creation of production-like data for lower trust environments: Using a product like ALTR’s FPE, data engineers can use the cipher-text of production data to create useful mock datasets for consumption by developers in lower-trust development and test environments.
Security Challenges and Benefits of Using Padding in FPE
Padding is a technique used in encryption to ensure that the plaintext data meets the required minimum length for the encryption algorithm. While padding is beneficial in maintaining data structure, it presents both advantages and challenges in the context of FPE:
Benefits of Padding
1. Consistency in Data Length: Padding ensures that the data conforms to the required minimum length, which is necessary for the encryption algorithm to function correctly.
2. Preservation of Data Format: Padding helps maintain the original data format, which is crucial for systems that rely on specific data structures.
3. Enhanced Security: By adding extra data, padding can make it more difficult for attackers to infer information about the original data from the ciphertext.
Security Challenges of Padding
1. Increased Complexity: The use of padding adds complexity to the encryption and decryption processes, which can increase the risk of implementation errors.
2. Potential Information Leakage: If not implemented correctly, padding schemes can potentially leak information about the original data, compromising security.
3. Handling of Padding in Decryption: Ensuring that the padding is correctly handled during decryption is crucial to avoid errors and data corruption.
Wrapping Up
ALTR's Format Preserving Encryption, powered by the technically robust FF3-1 algorithm and married with legendary ALTR policy, offers a comprehensive solution for encrypting sensitive data while maintaining its usability and format. This approach ensures compatibility with existing systems, enhances data security, and supports regulatory compliance. However, the use of padding in FPE, while beneficial in preserving data structure, introduces additional complexity and potential security challenges that must be carefully managed. By leveraging ALTR’s FPE, organizations can effectively protect their sensitive data without sacrificing functionality or performance.
For more information about ALTR’s Format Preserving Encryption and other data security solutions, visit the ALTR documentation
For years (even decades) sensitive information has lived in transactional and analytical databases in the data center. Firewalls, VPNs, Database Activity Monitors, Encryption solutions, Access Control solutions, Privileged Access Management and Data Loss Prevention tools were all purchased and assembled to sit in front of, and around, the databases housing this sensitive information.
Even with all of the above solutions in place, CISO’s and security teams were still a nervous wreck. The goal of delivering data to the business was met, but that does not mean the teams were happy with their solutions. But we got by.
The advent of Big Data and now Generative AI are causing businesses to come to terms with the limitations of these on-prem analytical data stores. It’s hard to scale these systems when the compute and storage are tightly coupled. Sharing data with trusted parties outside the walls of the data center securely is clunky at best, downright dangerous in most cases. And forget running your own GenAI models in your datacenter unless you can outbid Larry, Sam, Satya, and Elon at the Nvidia store. These limits have brought on the era of cloud data platforms. These cloud platforms address the business needs and operational challenges, but they also present whole new security and compliance challenges.
ALTR’s platform has been purpose-built to recreate and enhance these protections required to use Teradata for Snowflake. Our cutting-edge SaaS architecture is revolutionizing data migrations from Teradata to Snowflake, making it seamless for organizations of all sizes, across industries, to unlock the full potential of their data.
What spurred this blog is that a company reached out to ALTR to help them with data security on Snowflake. Cool! A member of the Data & Analytics team who tried our product and found love at first sight. The features were exactly what was needed to control access to sensitive data. Our Format-Preserving Encryption sets the standard for securing data at rest, offering unmatched protection with pricing that's accessible for businesses of any size. Win-win, which is the way it should be.
Our team collaborated closely with this person on use cases, identifying time and cost savings, and mapping out a plan to prove the solution’s value to their organization. Typically, we engage with the CISO at this stage, and those conversations are highly successful. However, this was not the case this time. The CISO did not want to meet with our team and practically stalled our progress.
The CISO’s point of view was that ALTR’s security solution could be completely disabled, removed, and would not be helpful in the case of a compromised ACCOUNTADMIN account in Snowflake. I agree with the CISO, all of those things are possible. Here is what I wanted to say to the CISO if they had given me the chance to meet with them!
The ACCOUNTADMIN role has a very simple definition, yet powerful and long-reaching implications of its use:
One of the main points I would have liked to make to the CISO is that as a user of Snowflake, their responsibility to secure that ACCOUNTADMIN role is squarely in their court. By now I’m sure you have all seen the news and responses to the Snowflake compromised accounts that happened earlier this year. It is proven that unsecured accounts by Snowflake customers caused the data theft. There have been dozens of articles and recommendations on how to secure your accounts with Snowflake and even a mandate of minimum authentication standards going forward for Snowflake accounts. You can read more information here, around securing the ACCOUNTADMIN role in Snowflake.
I felt the CISO was missing the point of the ALTR solution, and I wanted the chance to explain my perspective.
ALTR is not meant to secure the ACCOUNTADMIN account in Snowflake. That’s not where the real risk lies when using Snowflake (and yes, I know—“tell that to Ticketmaster.” Well, I did. Check out my write-up on how ALTR could have mitigated or even reduced the data theft, even with compromised accounts). The risk to data in Snowflake comes from all the OTHER accounts that are created and given access to data.
The ACCOUNTADMIN role is limited to one or two people in an organization. These are trusted folks who are smart and don’t want to get in trouble (99% of the time). On the other hand, you will have potentially thousands of non-ACCOUNTADMIN users accessing data, sharing data, screensharing dashboards, re-using passwords, etc. This is the purpose of ALTR’s Data Security Platform, to help you get a handle on part of the problem which is so large it can cause companies to abandon the benefits of Snowflake entirely.
There are three major issues outside of the ACCOUNTADMIN role that companies have to address when using Snowflake:
1. You must understand where your sensitive is inside of Snowflake. Data changes rapidly. You must keep up.
2. You must be able to prove to the business that you have a least privileged access mechanism. Data is accessed only when there is a valid business purpose.
3. You must be able to protect data at rest and in motion within Snowflake. This means cell level encryption using a BYOK approach, near-real-time data activity monitoring, and data theft prevention in the form of DLP.
The three issues mentioned above are incredibly difficult for 95% of businesses to solve, largely due to the sheer scale and complexity of these challenges. Terabytes of data and growing daily, more users with more applications, trusted third parties who want to collaborate with your data. All of this leads to an unmanageable set of internal processes that slow down the business and provide risk.
ALTR’s easy-to-use solution allows Virgin Pulse Data, Reporting, and Analytics teams to automatically apply data masking to thousands of tagged columns across multiple Snowflake databases. We’re able to store PII/PHI data securely and privately with a complete audit trail. Our internal users gain insight from this masked data and change lives for good.
- Andrew Bartley, Director of Data Governance
I believed the CISO at this company was either too focused on the ACCOUNTADMIN problem to understand their other risks, or felt he had control over the other non-admin accounts. In either case I would have liked to learn more!
There was a reason someone from the Data & Analytics team sought out a product like ALTR. Data teams are afraid of screwing up. People are scared to store and use sensitive data in Snowflake. That is what ALTR solves for, not the task of ACCOUNTADMIN security. I wanted to be able to walk the CISO through the risks and how others have solved for them using ALTR.
The tools that Snowflake provides to secure and lock down the ACCOUNTADMIN role are robust and simple to use. Ensure network policies are in place. Ensure MFA is enabled. Ensure you have logging of ACCOUNTADMIN activity to watch all access.
I wish I could have been on the conversation with the CISO to ask a simple question, “If I show you how to control the ACCOUNTADMIN role on your own, would that change your tone on your teams use of ALTR?” I don’t know the answer they would have given, but I know the answer most CISO’s would give.
Nothing will ever be 100% secure and I am by no means saying ALTR can protect your Snowflake data 100% by using our platform. Data security is all about reducing risk. Control the things you can, monitor closely and respond to the things you cannot control. That is what ALTR provides day in and day out to our customers. You can control your ACCOUNTADMIN on your own. Let us control and monitor the things you cannot do on your own.
Since 2015 the migration of corporate data to the cloud has rapidly accelerated. At the time it was estimated that 30% of the corporate data was in the cloud compared to 2022 where it doubled to 60% in a mere seven years. Here we are in 2024, and this trend has not slowed down.
Over time, as more and more data has moved to the cloud, new challenges have presented themselves to organizations. New vendor onboarding, spend analysis, and new units of measure for billing. This brought on different cloud computer-related cost structures and new skillsets with new job titles. Vendor lock-in, skill gaps, performance and latency and data governance all became more intricate paired with the move to the cloud. Both operational and transactional data were in scope to reap the benefits promised by cloud computing, organizational cost savings, data analytics and, of course, AI.
The most critical of these new challenges revolve around a focus on Data Security and Privacy. The migration of on-premises data workloads to the Cloud Data Warehouses included sensitive, confidential, and personal information. Corporations like Microsoft, Google, Meta, Apple, Amazon were capturing every movement, purchase, keystroke, conversation and what feels like thought we ever made. These same cloud service providers made this easier for their enterprise customers to do the same. Along came Big Data and the need for it to be cataloged, analyzed, and used with the promise of making our personal lives better for a cost. The world's population readily sacrificed privacy for convenience.
The moral and ethical conversation would then begin, and world governments responded with regulations such as GDPR, CCPA and now most recently the European Union’s AI Act. The risk and fines have been in the billions. This is a story we already know well. Thus, Data Security and Privacy have become a critical function primarily for the obvious use case, compliance, and regulation. Yet only 11% of organizations have encrypted over 80% of their sensitive data.
With new challenges also came new capabilities and business opportunities. Real time analytics across distributed data sources (IoT, social media, transactional systems) enabling real time supply chain visibility, dynamic changes to pricing strategies, and enabling organizations to launch products to market faster than ever. On premise applications could not handle the volume of data that exists in today’s economy.
Data sharing between partners and customers became a strategic capability. Without having to copy or move data, organizations were enabled to build data monetization strategies leading to new business models. Now building and training Machine Learning models on demand is faster and easier than ever before.
To reap the benefits of the new data world, while remaining compliant, effective organizations have been prioritizing Data Security as a business enabler. Format Preserving Encryption (FPE) has become an accepted encryption option to enforce security and privacy policies. It is increasingly popular as it can address many of the challenges of the cloud while enabling new business capabilities. Let’s look at a few examples now:
Real Time Analytics - Because FPE is an encryption method that returns data in the original format, the data remains useful in the same length, structure, so that more data engineers, scientists and analysts can work with the data without being exposed to sensitive information.
Proactive Data Security– FPE allows for the anonymization of sensitive information, proactively protecting against data breaches and bad actors. Good holding to ransom a company that takes a more proactive approach using FPE and other Data Security Platform features in combination.
Empowered Data Engineering – with FPE data engineers can still build, test and deploy data transformations as user defined functions and logic in stored procedures or complied code will run without failure. Data validations and data quality checks for formats, lengths and more can be written and tested without exposing sensitive information. Federated, aggregation and range queries can still run without fail without the need for decryption. Dynamic ABAC and RBAC controls can be combined to decrypt at runtime for users with proper rights to see the original values of data.
Cost Management – While FPE does not come close to solving Cost Management in its entirety, it can definitely contribute. We are seeing a need for FPE as an option instead of replicating data in the cloud to development, test, and production support environments. With data transfer, storage and compute costs, moving data across regions and environments can be really expensive. With FPE, data can be encrypted and decrypted with compute that is a less expensive option than organizations' current antiquated data replication jobs. Thus, making FPE a viable cost savings option for producing production ready data in non-production environments. Look for a future blog on this topic and all the benefits that come along.
FPE is not a silver bullet for protecting sensitive information or enabled these business use cases. There are well documented challenges in the FF1 and FF3-1 algorithms (another blog on that to come). A blend of features including data discovery, dynamic data masking, tokenization, role and attribute-based access controls and data activity monitoring will be needed to have a proactive approach towards security within your modern data stack. This is why Gartner considers a Data Security Platform, like ALTR, to be one of the most advanced and proactive solutions for Data security leaders in your industry.
Securing sensitive information is now more critical than ever for all types of organizations as there have been many high-profile data breaches recently. There are several ways to secure the data including restricting access, masking, encrypting or tokenization. These can pose some challenges when using the data downstream. This is where Format Preserving Encryption (FPE) helps.
This blog will cover what Format Preserving Encryption is, how it works and where it is useful.
What is Format Preserving Encryption?
Whereas traditional encryption methods generate ciphertext that doesn't look like the original data, Format Preserving Encryption (FPE) encrypts data whilst maintaining the original data format. Changing the format can be an issue for systems or humans that expect data in a specific format. Let's look at an example of encrypting a 16-digit credit card number:
As you can see with a Standard Encryption type the result is a completely different output. This may result in it being incompatible with systems which require or expect a 16-digit numerical format. Using FPE the encrypted data still looks like a valid 16-digit number. This is extremely useful for where data must stay in a specific format for compatibility, compliance, or usability reasons.
Format Preserving Encryption in ALTR works by first analyzing the column to understand the input format and length. Next the NIST algorithm is applied to encrypt the data with the given key and tweak. ALTR applies regular key rotation to maximize security. We also support customers bringing their own keys (BYOK). Data can then selectively be decrypted using ALTR’s access policies.
Why use Format Preserving Encryption
FPE offers several benefits for organizations that deal with structured data:
1. Adds extra layer of protection: Even if a system or database is breached the encryption makes sensitive data harder to access.
2. Original Data Format Maintained: FPE preserves the original data structure. This is critical when the data format cannot be changed due to system limitations or compliance regulations.
3. Improves Usability: Encrypted data in an expected format is easier to use, display and transform.
4. Simplifies Compliance: Many regulations like PCI-DSS, HIPAA, and GDPR will mandate safeguarding, such as encryption, of sensitive data. FPE allows you to apply encryption without disrupting data flows or reporting, all while still meeting regulatory requirements.
When to use Format Preserving Encryption?
FPE is widely adopted in industries that regularly handle sensitive data. Here are a few common use cases:
Healthcare: Hospitals and healthcare providers could use FPE to protect Social Security numbers, patient IDs, and medical records. It ensures sensitive information is encrypted while retaining the format needed for billing and reporting.
Telecoms: Telecom companies can encrypt phone numbers and IMSI (International Mobile Subscriber Identity) numbers with FPE. This allows the data to be securely transmitted and processed in real-time without decryption.
Government and Defense: Government agencies can use FPE to safeguard data like passport numbers and classified information. Preserving the format ensures seamless data exchange across systems without breaking functionality.
Data Sharing: In this blog we talk about how FPE can help with Snowflake Data Sharing use cases.
Wrapping Up
ALTR offers various masking, tokenization and encryption options to keep all your Snowflake data secure. Our customers are seeing the benefit of Format Preserving Encryption to enhance their data protection efforts while maintaining operational efficiency and compliance. For more information, schedule a product tour or visit the Snowflake Marketplace.
January 28
8 min
ALTR Featured as a Founding Partner of the Snowflakes Horizon Ecosystem 1
January 28
8 min
ALTR Featured as a Founding Partner of the Snowflakes Horizon Ecosystem 1
January 28
8 min
ALTR Featured as a Founding Partner of the Snowflakes Horizon Ecosystem 1
January 28
8 min
ALTR Featured as a Founding Partner of the Snowflakes Horizon Ecosystem 1
Browse All
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.
Data protection and data privacy have continued to appear on the front page of local and national news throughout the year and as we close the final chapters of 2022. Remote work and scattered teamwork continue for many, pulling IT, governance, data and security teams in disparate directions, often not allowing the capacity to face data privacy and protection issues. We saw that reflected throughout the year in the many trending topics and news headlines.
Without further ado, we present our 2022 Data Wrapped:
The 'Next Big Thing' in Cyber Security
15 industry experts from Forbes Technology Council, including ALTR CEO James Beecham, discuss cybersecurity awareness and key items every organization’s leadership team should take note of. Read More
US Federal Data Privacy Law Looks More Likely
While the United States doesn't have a federal data privacy law yet, in May of this year, legislators introduced the Data Privacy and Protection Act “which is a major step forward by Congress in its two-decade effort to develop a national data security and digital privacy framework that would establish new protections for all Americans.” In addition, 5 US States have data privacy legislation going into effect in 2023.
75% of the World Will Be Covered by Data Privacy Regulations
Whether your company exists in a state with data legislation or not, now is the time to think about protecting your sensitive cloud-based data. Gartner predicts that “by year-end 2024, 75% of the world’s population will have its personal data covered under modern privacy regulations.” Europe led the charge in formalizing modern privacy laws with the GDPR, a bill that passed in 2018 regulating the handling of sensitive data. And while the United States is still catching up on state-by-state laws, Gartner believes that due to the COVID-19 pandemic and rising cases of data breaches, security and risk management (SRM) will only gain in prevalence as we move into the new year.
Data Breaches Continue to Make Headlines in 2022
Unfortunately, data theft continued to be a prevalent issue in 2022, with Apple, Meta, Twitter, and Uber being among the list of companies who suffered significant data breaches. We're seeing data breaches this year, even more than years past, impact companies across all sectors and sizes.
In September of 2022, Uber's computer network suffered a "total compromise" due to a hacker wrongfully gaining access to their data. Email, cloud storage and code repository data were all breached. The hacker, an 18-year-old, told The New York Times that Uber was an easy target for him "because the company had weak security." Read more here.
ALTR Maintained Market Momentum Throughout 2022
In March 2022, Q2 Holdings, Inc a leading provider of digital transformation solutions for banking and lending, and ALTR announced the long-term extension and expansion of their strategic technology partnership through 2026 to deliver unrivaled data governance and security to Q2 financial institution customers. Learn more here.
In June, ALTR announced the expansion of its partnership with Snowflake with the release of its new policy automation engine for managing data access controls in Snowflake and beyond. This solution allowed data engineers and architects to set up data access policies in minutes, manage ongoing updates to data permissions, and handle data access requests through ALTR’s own no-code platform for data policy management.
And in October, ALTR Co-founder and Chief Technology Officer, James Beecham, became ALTR’s newest Chief Executive Officer. Beecham leverages his technical acumen and passion for the industry and the business to lead the company's next phase of accelerated expansion. ALTR also appointed Co-founder and Vice President Engineering, Chris Struttmann, to the Chief Technology Officer position. Previous CEO David Sikora remains actively involved with ALTR as a Board Director, CEO Advisor and financial investor.
Looking Forward to 2023
We anticipate 2023 will continue to prove the urgency of focusing on the protection of your sensitive data, making now the time to create your action plan to protect your data. ALTR's low up-front-cost, no-code data governance solution is a great place to begin. Are you ready to take the next step in controlling access to your sensitive data? We can't wait to show you how ALTR can help.
Determining how to handle home security to protect your family is critical. After all, you don’t want to take risks when it comes to their safety. It’s an easy thing to put a lock on one door. But what about every door in the house? Every window? What if you need to handle security for the whole neighborhood? That’s when manual and DIY become unmanageable.
Snowflake database admins and data owners can run into the same issue with Snowflake Row-Level Security. While it may seem a simple task to set up one row access policy for one database using SQL in Snowflake, it quickly becomes overwhelming when you have hundreds of new users requesting access each week or thousands of rows of new data coming into your system daily.
In this blog post, we’ll explain what Snowflake Row-Level Security is and:
Lay out the steps to set up Snowflake Row-Level Security policies manually using SQL vs setting up and managing these policies, with no code, in ALTR
Provide examples of row-access policy use cases
Show how using ALTR’s Row Access Policy feature can help minimize errors and make managing Snowflake row level security easier for anyone responsible for data security.
What is Snowflake Row-Level Security?
Snowflake’s row-level security allows you to hide or show individual rows in an SQL data table based on the user's role. This level of security gives you greater control of who you’re permitting to access sensitive data. For example, you may want to prevent personally identifiable data (PII) held in rows in a customer table from being visible to your call center agents based on the customers’ address. By using our ALTR Row Access Policy feature you will save:
overhead costs from having to hire multiple developers to handle the work,
developer time to manually write code, and
effort to make configurations correctly when you need to restrict access to individual rows within a table.
How Creating Snowflake Row-Level Security Policies Works if you DIY
What’s involved to create a row-level security policy in Snowflake:
Who can do it: A software developer who knows how to manually write SQL code
Length of time to complete successfully: Hours or even days each week because the developer will have to manually do-it-yourself (DIY)
Each of the steps below requires code reviews, QA, validation, and maintenance that must be done. These tasks can cause this to take weeks to complete for each unique row access policy.
1. Grant the custom role to a user.
2. Write some code to determine if a table already has a row access policy defined.
3. Write some code to get the original row policy code if it was already defined.
4. Edit the code (or write new code) to implement the row access policy.
Step 4 is what will require most of your time because of everything that’s involved. For example, identifying all the criteria that could give a user access to a role, getting all department stakeholders to approve, turning those conditions into code, and having someone else to review that code and test it are all tasks to complete.
In addition, you’ll also need to make edits based on the code reviews and tests and constantly update the code each time the criteria changes.
How Creating Snowflake Row-Level Security Policies Works in ALTR
What’s involved to create a row access policy in ALTR:
Who can do it: Anyone
Length of time to complete successfully: Minutes because ALTR requires no code to implement and automates the security process
1. On the Row Access Policy page of our UI, select Add New.
This will allow you to specify the table that the Row Access Policy will apply to and the reference column that will control access.
ALTR Row Access Policy page
2. Indicate which Snowflake roles can access certain rows based on the values in a column. To do this, specify the mappings between User Groups (Snowflake Roles) and column values.
Table and Reference column to apply the access policy to
3. Review your policy, give it a name, click Submit, and you’re done. The name will be displayed in ALTR to reference the Row Access Policy. ALTR will convert the Row Access Policy into Snowflake. In just a few seconds, ALTR will insert the active policy into Snowflake!
Snowflake Row-Level Security Use Cases
Here are a couple of example use cases where our Row Access Policy feature in ALTR can benefit your business as it scales with your Snowflake usage.
USE CASE 1. Using Row-Level Policies to Enable Regional Sales Views
You have sales data that includes records for sales in all your sales regions. You only want your sales managers to see the data for the regions that they manage.
USE CASE 2. Using Row-Level Policies to Enable Separate Data Sets
You run a SaaS business and your customers want a data set for report of their transactions in your product; however, all the transactions are in a single table — the SaaS way.
What you could be doing: Automating your Snowflake Row-Level Security Policies with ALTR
Do you or your team have hours in a day to spend manually writing SQL code every time you need to create a unique row access policy for hundreds or thousands of users? Do you want to have to increase overhead by hiring multiple developers to manually create row access policies and manage them? Do you want to have to spend hours trying to figure out why a Snowflake row-access policy is not working correctly and you’re getting error messages?
While you can still choose to go down the SnowSQL do-it-yourself route, why not work smart instead of hard? Why risk data breaches and regulatory fines? Safeguard your data to make sure that only the right people have the right access.
By now, you have a better understanding of how using ALTR’s no-code platform enables users who don’t need to know SQL to create and manage Snowflake row level security through a simple point-and-click UI
Watch the “how-to” comparison video below to see manually setting up your own Snowflake Row Access Security Policy versus doing it with ALTR.
Cloud data migration is an inevitable part of every organization’s digital transformation journey. While a big data migration project can seem like an intimidating process, it doesn’t have to be. In fact, with the right preparation and implementation strategy, your organization can use your cloud migration as an opportunity to streamline internal processes, improve data security, reduce costs and gain insights.
To help you avoid some common pitfalls in your cloud data migration, we’ve put together this comprehensive guide with everything you need to know about moving data to the cloud. This post covers everything from why you should migrate to the cloud to what types of data you should migrate and how to do it securely. Let’s get started!
What is Cloud Data Migration?
Cloud data migration is the process of migrating data from on-premises systems to cloud-based systems. When migrating data to the cloud, it’s important to keep in mind that not all data is created equal. There are different types of data that each have unique needs when it comes to migration. While some data types can be migrated easily, others require a more careful approach that takes special considerations into account.
Why Tackle a Cloud Data Migration?
Cloud data migration is often a key step on the journey towards becoming a data-driven organization. Cloud data migration provides organizations with the opportunity to re-evaluate how they use data and make improvements to their data management processes. As part of your digital transformation journey, cloud migration allows you to transform data into a strategic asset by creating a centralized access point for all your organization’s data. This means data can be more easily retrieved, managed, and integrated across the enterprise. Moving data to the cloud not only provides access to more scalable computing resources than you may have on-premises, it also gives you admittance to a wide range of software-as-a-service (SaaS) apps that you can use to collaborate, process data, and collect insights. This access to a variety of business applications through a single user interface allows organizations to seamlessly integrate various functions and workflows within the organization.
How to Know Which Data to Include in Your Cloud Data Migration?
The best way to decide which data to migrate to the cloud is to start with your business objectives. Once you know what you want to achieve with your cloud data migration, you can start deciding which data to move. There are a few common objectives that most organizations have when it comes to data. These include:
increasing employee productivity,
improving customer experience, and
boosting operational efficiency.
You should also consider moving data that is used frequently and is accessed by various departments. If a data source is critical to business operations, it should be migrated. This includes data such as employee data, customer data, and device data.
Migrating Device and Sensor Data to the Cloud
Moving device and sensor data to the cloud makes it easier to collect and analyze this type of data. This data can be collected from a wide variety of sources, including IoT devices and sensors. Moving device and sensor data to the cloud will allow you to store this data in a central location. Moving device and sensor data to the cloud will also make it easier to integrate this data with other systems such as data analytics tools and CRM systems like Salesforce. Doing so will help you generate more insightful business insights and make more strategic decisions.
Migrating Customer Data to the Cloud
Moving customer data to the cloud will give you access to a wide variety of customer data analytics tools. This will allow you to better understand your customer base and make strategic business decisions based on customer insights. Moving customer data to the cloud will give you access to data management tools that allow you to collect, organize, and analyze information such as customer data, purchase history, and account information. This will help you make more strategic business decisions, provide better customer service, and identify new business opportunities. Moving customer data to the cloud can also help you comply with data privacy regulations, including the GDPR.
Migrating Business-Critical Data to the Cloud
When deciding which data to migrate to the cloud, you should consider moving data that is most relevant to your business. Moving business-critical data to the cloud will give you access to more computing resources than what you may have on-premises and will allow you to scale up your data processing when needed. Moving business-critical data to the cloud will also deliver access a wide range of data analytics tools such as Tableau, Thoughtspot or Looker that will help you generate more helpful business insights.
Migrating Employee Data to the Cloud
Moving employee data to the cloud will give you access to cloud-based HR tools that can help you manage key business functions such as hiring, onboarding, and payroll. Moving data such as employee contact information, payroll data, internal and external communications, and customer information to the cloud can improve collaboration across departments by enabling real-time access to information. This access can be particularly beneficial for customer-facing teams such as sales and customer service.
Migrating Sensitive Data to the Cloud Securely
Employee data, device and sensor data, customer data and business critical data can all comprise sensitive information that is either regulated like personally identifiable information (PII) or simply extremely valuable to the company like intellectual property or payroll information. When moving that data away from company owned on-premises systems and data centers, controlling access and ensuring security throughout the journey is required. There are several places along the cloud data migration path that a cloud data security tool like tokenization can be implemented – from the on-prem warehouse to the cloud, as soon as it leaves the on-prem warehouse but before its handed off to an ETL, or as it enters the cloud data warehouse. The right process will often depend on how sensitive your data is and how regulated your industry is.
Cloud Data Migration Ecosystem
Part of moving data to the cloud is choosing the right tools for the migration itself (ETL), where to store and share the data (Cloud Data Warehouses), and how to analyze the data (Business Intelligence tools). Today's modern data ecosystem solutions are gathered and reviewed for you here. Your goal should be to build a modern data ecosystem tool stack that integrates easily and works together to deliver the data sharing and analytic goals of your cloud data migration project.
Wrapping up
If your organization has been using traditional systems, a cloud data migration may seem like an overwhelming process. To make it easier, first start by identifying the data types you want to migrate to the cloud. Moving customer data to the cloud, for example, will give you access to better customer analytics tools. Moving employee data to the cloud, on the other hand, will allow you to manage key business functions such as hiring, onboarding, and payroll. Knowing which data to move to the cloud is the first step towards successfully migrating to the cloud. Once you know what to migrate, and the security measures your data requires, you can start the process of planning and implementing your cloud data migration.
In the last year, we’ve seen the awareness of the need for data access control and security in cloud data warehouses pass an inflection point. Most companies we talk to now, especially in the FinServ and Pharma industries, know they must have it. We don’t have to convince them sensitive data needs to be protected in the cloud or show them stats about data breaches or regulatory fines. They get it. But how they decide to get to it is a different story. Some decide to go down the do-it-yourself or build-it-yourself route, but I’m here to explain why you shouldn’t.
Automation Greases the Wheels
Identity providers like Okta and Active Directory have done a great job of enabling companies to automatically generate as many users and roles in Snowflake as needed. Today admins can go from 0 users to 1000 in about an hour or two.
On the other side of the equation, ETL providers like Matillion, FiveTran and Talend have made it easy for companies to transport their data into Snowflake. In an hour or two, admins can move gigabytes or even terabytes of source data and have it ready and waiting for users to access.
These two forces come to a head at the intersection between them: connecting users with data and defining the relationships between them. How do you make sure only the right users have access to only the data they should have?
Enter BIY Data Access Controls
Many companies start with DIY or do-it-yourself: the trusty Snowflake admin or DBA decides to write a handful of SnowSQL Snowflake data access control policies, one at a time. This works when you have one or two new users a week requesting access. But chances are, if you’re using an identity provider to create your profiles, you’re already dealing in hundreds or even thousands of users. DIY just doesn’t cut it – doing that work can suck up hours or even days each week, bringing access for new users as well as any other data projects to a halt, not to mention the human errors that can be introduced. It simply won’t scale.
Okay, so then our ingenious database admin thinks, “I can BIY this” or build-it-yourself. “I have a tool that puts my users in automatically. And I have a tool that puts my data in automatically. I can fix this problem if I just spend the next week writing a tool that automatically connects these two domains together. Easy-peasy.”
But wait, let’s take a step back and think about this. Snowflake also gives admins a way to add users without an identity management tool and add their data without an ETL tool. So, what’s the advantage of using an Okta or Matillion? The answer is reliability, scale and automation – those software vendors have built solutions that save you time and just do it better.
Risk of Crossing the Streams – User x Data
It’s ironic that of the tools they could create on their own, some companies focus on connecting users with data. Obviously, they’re doing this because they haven’t yet found the Okta or Matillion to handle this. But the irony is that this is the most dangerous spot in the process – that intersection is actually where all the risks are.
You can add data to Snowflake, and it’s pretty safe when users can’t get to it. And you can add users to Snowflake, but they can’t do much without access to data. Very rarely do you get in trouble for adding a wrong user or the wrong data. If users aren’t connected to the data, the risk is near zero. It’s in the middle part where the streams cross that is fraught with risk. Connecting the wrong user with the wrong data can be very bad for a data engineer, data steward, or privacy owner.
You could BIY, but Are You Enterprise-Ready?
So, an admin can write a quick and dirty Snowflake masking policy, but can others read and work with it? Do you have a QA team to eliminate errors? Once you get a proof-of-concept to work on one or two databases, can you ensure it scales correctly and can run quickly across thousands? Do you have the time to integrate it with Okta or Matillion or Splunk? Do you have a roadmap that ensures it’s staying in sync with new private-preview Snowflake features, keeping up with your changing data and regulatory landscape, and addressing new user service needs? Can you ensure it actually works correctly – did you build in feedback and alerting on fails and errors?
In other words, do you want to hire 30 engineers and spend millions of dollars to build enterprise-ready software you can trust with the risky connection between users and data?
Automated Snowflake Data Access Control for the Win
Wouldn’t it just be easier to grab a third leg of your stool for data access controls to go with your user role and data transfer solutions? That’s where ALTR comes in. We’ve already invested the time and resources to build a world-class, reliable solution that automates and enforces the connection between users and data. It leverages all of Snowflake’s native data governance features while adding a no-code layer that makes it easy to apply and manage. It also shows you how users are accessing data to be confident that data is shared correctly. And because it’s SaaS, it’s fast to implement, starts at a low cost and can scale with your Snowflake usage – to hundreds of users and thousands of databases. (You could even think of it as Okta for Data.)
Want to try it today? Sign up for our Free Plan. Or get a Demo to see how ALTR’s enterprise-ready solution can handle data access control for you. And avoid the BIY headache before it starts.
Today Christian Kleinerman (SVP Product, Snowflake) grouped his keynote announcements and discussions into three broad areas: core platform, data cloud content, and building on Snowflake.
There was certainly a bit of excitement in the air as it relates to partners at the keynote. Christian continued to emphasize partners, and he started off by repeating a thought from the other Data Cloud World Tours which is that Snowflake is one product. I think this message needs to remain in front of the partner mind: Snowflake will continue to encourage partners to invest in the single platform and will be unsupportive of any partner who wants to create a non-unified experience with Snowflake.
Snowflake Core Platform
Under the core platform pillar some of the big announcements centered on cross-cloud availability and replication which can make Snowflake a much safer platform to run your business on, especially at global scale. One big shout out for partners was the announcement around data listing analytics. If you are a data provider partner for Snowflake, this is a big win for you. Understanding how consumers are using your data listings will ensure you can make the best decisions as you look to add or remove data sets.
For the governance and security partners, these cross-cloud replication and failovers might cause some issues depending upon how your solution is implemented. For users of tokenization or external functions in general, we know there might still be some need for Snowflake to continue to invest in this area so governance and security features can also seamlessly failover.
Snowflake Data Cloud Content
The second pillar around data cloud content was focused on producing applications and workloads on Snowflake. Partners like EY, phData and Infosys were specifically called out. And it was clear these partners were in the crowd as there was some unexpected cheering! If you are not thinking about building an application natively inside of Snowflake this part of the talk would have you reconsidering. A new partner/ecosystem new startup called Samooha was brought on stage. In under 6 months, the company went from mockup to full working product to help build clean rooms within Snowflake. They noted it was still really new but showcases how quickly you can build an MVP and bring a value-added process to market directly in Snowflake.
Building on Snowflake
Snowpark for Python is now GA! This was the biggest announcement from the last segment around building on snowflake. They actually produced fake snow in the room to make it a true ‘snowday’! Partners can now have a secure single place in Snowflake to share data and run python models directly on data inside of snowflake. This is huge for partners. Christian noted a 6x uptick in usage since the initial announcement at Snowflake Summit ‘22.
Streamlit can be run directly in Snowflake, which will make building and selling an application inside of Snowflake much easier, was a big deal as well. This will make it much easier for users to consume these applications as data will no longer need to leave Snowflake.
It was great to see Sri Chintala on the stage. I remember two years ago when we were first looking at becoming a Snowflake partner, Sri was one of the first product folks we talked with. At the time she was leading the external function group which ALTR utilized heavily. Now she is working with python use cases and got the chance to demo her latest work on stage. It’s amazing to see the product folks mature and with that maturity continue to bring partners, like Anaconda who Sri mentioned on stage, along with them. She also did a good job handling those microphone issues!
All in all, it was another exciting Snowday, and ALTR is looking forward to the next six months as a Snowflake partner. I’ll be posting some thoughts on what I hear throughout the day on LinkedIn. Catch me there until next time!
Today’s business environment is awash with data. From product development intellectual property (IP) to customer personally identifiable information (PII) to logistics and supply chain information, data is coming at us from all directions. And that data is making its way throughout the business in ways that it never did before.
In the past, your customer and prospect data may have stayed securely behind a firewall in a customer database in a company-owned datacenter. But from the moment Salesforce launched its pioneering Software-as-a-Service CRM, that data has been moving into the cloud. And the volume has only increased. Now, cloud data platforms like Snowflake and Amazon Redshift offer anyone the ability to host and analyze data with just a credit card and a spreadsheet. This has opened a pandora’s box of data analysis possibilities that comes with attendant challenges and risks.
By now most companies understand the significant opportunities presented by living in the “Age of Data.” Recently, a data ecosystem of technologies has developed to help organizations take advantage of these new opportunities. In fact, so many new tools, solutions and technologies have appeared that choosing solutions for a modern data ecosystem can be almost as difficult as dealing with data itself.
We put together this guide to help clear the clutter and explain who does what in the modern data ecosystem and how it can help your organization become more data-driven more quickly.
Your Data Ecosystem Guide
Data Discovery, Classification, and Catalogs
The rapid growth of data collection, security threats, and regulatory requirements has transformed what was previously an esoteric process conversation into a mainstream business challenge. It’s now a strategic priority for any organization to apply and enforce data governance standards, not just the traditional regulated industries like finance and healthcare. However, data owners must tread carefully to avoid running up against privacy laws like GDPR and CCPA: Gartner believes that modern privacy regulations will cover 75% of the world in a couple of years.
Many vendors focus on “knowing” your data—where it is (discovery), what is it (classification), where it came from (data lineage). Industry analysts call this “metadata management,” or getting a handle on the data itself. Data discovery, classification and cataloging are the critical first steps of a bigdata ecosystem.
Alationis credited with creating the data catalog product category – an early building block of the modern data ecosystem. Its signature software, the Alation Data Catalog, serves enterprises in organizing and consolidating their data. Alation’s enterprise data catalog dramatically improves the productivity of analysts, increases the accuracy of analytics, and drives confident data-driven decision making while empowering everyone in your organization to find, understand, and govern data.
BigID offers software for managing sensitive and private data, completely rethinking data discovery and intelligence for the privacy era. BigID was the first company to deliver enterprises the technology to know their data to the level of detail, context and coverage they would need to meet core data privacy protection requirements. BigID’s data intelligence platform enables organizations to take action for privacy, protection, and perspective. Organizations can deploy BigID to proactively discover, manage, protect, and get more value from their regulated, sensitive, and personal data across their data landscape.
Collibra calls itself “The Data Intelligence Company.” They aim to remove the complexity of data management to give you the perfect balance between powerful analytics and ease of use. The company’s premier offering is its data catalog – a single solution for teams to easily discover and access reliable data. It allows companies to provide users access to trusted data across all your data sources. Delivering this end-to-end visibility starts with your data catalog, and Collibra gets you up and running in days. With Collibra’s scalable platform, you can future-proof your investment, no matter where business takes you next.
Cloud Data Warehouses
While the cloud migration started with specific workloads moving to SaaS services (think Salesforce or Office 365), today the data ecosystem is focused on, well, data. The same advantages of SaaS – low up-front costs, no hardware to maintain, no datacenter to staff and service, no upgrades to track – all apply to the modern cloud data warehouse. In addition, data storage combined with compute enables companies to consolidate data from across the company and make it easily available for analysis and insight. Data-driven companies find this service invaluable.
Snowflake offers a cloud-based data storage and analytics service that allows users to store and analyze data using cloud-based hardware and software. Snowflake’s founders engineered Snowflake to power the Data Cloud, where thousands of organizations have smooth access to explore, share, and unlock the full value of their data. Today, 1300 Snowflake customers have more than 250PB of data managed by the Data Cloud, with more than 515 million data workloads that run each day.
According to the company, tens of thousands of companies rely on Amazon Redshift to analyze exabytes of data with complex analytical queries, making it the most widely used cloud data warehouse. Users can run and scale analytics in seconds on all their data without having to manage a data warehouse infrastructure. Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and data lakes. With AWS-designed hardware and machine learning, the service can deliver the best price performance at any scale. The company also offers a Free Tier.
The Databricks Lakehouse Platform combines the best elements of data lakes and data warehouses to deliver the reliability, strong governance and performance of data warehouses with the openness, flexibility and machine learning support of data lakes.
This unified approach simplifies your modern data stack by eliminating the data silos that traditionally separate and complicate data engineering, analytics, BI, data science and machine learning. It’s built on open source and open standards to maximize flexibility. And, its common approach to data management, security and governance helps you operate more efficiently and innovate faster.
ETL and ELT Providers
Another significant piece of the data ecosystem puzzle are ETL and ELT providers. Consolidating business data in cloud data warehouses like Snowflake is a smart move that can open up new doors of innovation and value. All your data in one place makes it easier to connect the dots in ways that were impossible or unimaginable before. For instance, a retail chain can optimize sales projections by analyzing weather patterns, or a logistics company can more accurately predict costs by accounting for the salaries of all the people involved in a shipment.
Getting to those insights is a process that starts with moving the data. An extract, transform, and load (ETL) migration technology partner simplifies moving or loading the data from each of your company’s locations into a cloud data warehouse to make it analytics-ready in no time. Moving data is what these companies do best.
Matillion’s complete data integration and transformation solution is purpose-built for the cloud and cloud data warehouses. The company’s flagship tool, Matillion ETL, is specifically for cloud database platforms including Amazon Redshift, Google BigQuery, Snowflake and Azure Synapse. It is a modern, browser-based UI, with powerful, push-down ETL/ELT functionality. Matillion ETL pushes down data transformations to your data warehouse and process millions of rows in seconds, with real-time feedback. The browser-based environment includes collaboration, version control, full-featured graphical job development, and more than 20 data read, write, join, and transform components. Users can launch and be developing ETL jobs within minutes. Matillion offers a free trial.
Focused on automated data integration, Fivetran delivers ready-to-use connectors that automatically adapt as schemas and APIs change, ensuring consistent, reliable access to data. In fact, the company says it offers the industry’s best selection of fully managed connectors. Their pipelines automatically and continuously update, freeing users up to focus on game-changing insights instead of ETL. They improve the accuracy of data-driven decisions by continuously synchronizing data from source applications to any destination, allowing analysts to work with the freshest possible data. To accelerate analytics, Fivetran automates in-warehouse transformations and programmatically manages ready-to-query schemas. Fivetran offers a free trial.
According to Talend integrating your data doesn't have to be complicated or expensive. Talend Cloud Integration Platform simplifies your ETL or ELT process, so your team can focus on other priorities. With over 900 components, you can move data from virtually any source to your data warehouse more quickly and efficiently than by hand-coding alone. Talent helps reduce spend, accelerate time to value, and deliver data you can trust.
Tableau is an interactive data visualization software company focused on business intelligence. Tableau products query relational databases, online analytical processing cubes, cloud databases, and spreadsheets to generate graph-type data visualizations. The software can also extract, store, and retrieve data from an in-memory data engine. Tableau allows organizations to ensure the responsible use of data and drive better business outcomes with fully-integrated data management and governance, visual analytics and data storytelling, and collaboration—all with Salesforce’s industry-leading Einstein built right in. Companies can lower the barrier to entry for users to engage and interact by building visualizations with drag and drop, employing AI-driven statistical modeling with a few clicks, and asking questions using natural language. Tableau provides efficiencies of scale to streamline governance, security, compliance, maintenance, and support with solutions for the entire lifecycle as the trusted environment for your data and analytics—from connection, preparation, and exploration to insights, decision-making, and action.
ThoughtSpot believes the world would be a better place if everyone had quicker, easier access to facts. Their search and AI-driven analytics platform makes it simple for anyone across the organization to ask and answer questions with data. It empowers colleagues, partners, and customers to turn data into actionable insights via the ThoughtSpot application, embedding insights into apps like Salesforce and Slack, or building entirely new data products. The consumer-grade search and AI technology delivers true self-service analytics that anyone can use, while the developer-friendly platform ThoughtSpot Everywhere makes it easy to build interactive data apps that integrate with users’ existing cloud ecosystem.
Looker Data & Analytics is business intelligence software and big data analytics platform that helps users explore, analyze and share real-time business analytics easily. Now part of Google Cloud, it offers a wide variety of tools for relational database work, business intelligence, and other related services. Looker utilizes a simple modeling language called LookML that lets data teams define the relationships in their database so business users can explore, save, and download data with only a basic understanding of SQL.[2] The product was the first commercially available business intelligence platform built for and aimed at scalable or massively parallel relational database management systems like Amazon Redshift, Google BigQuery and more.
ALTR continues to develop relationships with cloud data leaders across the industry. Our goal is to help our customers to get the most from their data by enabling a secure cloud data ecosystem that allows users to safely share and analyze sensitive data. Our scalable cloud platform acts as the foundation by enabling seamless integration with a wide variety of enterprise tools used to ingest, transform, store, govern, secure, and analyze data. ALTR has expanded how we interact with data ecosystem leaders via open-source integrations that allow users to freely and easily extend ALTR's data control and security to data catalogs like Alation and ETL tools like Matillion. Building a modern data ecosystem stack will set you firmly on the path to secure data-driven leadership.
If we’ve learned anything over the last few years, it’s that this data space moves faster than you can imagine. Whether it’s new investments from market leaders, new acquisitions, new partnerships, or new technologies, the landscape is always changing, and those who aren’t ready for the next big shift are quickly left behind.
James Beecham and Dave Sikora at BlackHat 2022
We anticipated this when we built the ALTR platform from the cloud up to be highly adaptable – our solution can easily scale up or scale down with users, with data, with cloud data warehouse usage. While our competitors were offering legacy on-prem solutions with high barriers to entry like long term commitments, massive up-front costs and complicated implementations, ALTR built a cloud-native, SaaS-based integration for Snowflake that users could add directly from Snowflake Partner Connect and a free plan that lets companies try our solution before ever paying a cent. Our decisions have paid off in market response, demonstrated by compounded annual revenue growth of over 300% since 2018 and an accelerating customer base of over 200 companies.
We couldn’t be more ready for the next phase in ALTR’s journey and it’s the perfect time to appoint a new leader to take it on: James Beecham, ALTR’s Co-founder and Chief Technology Officer has been promoted to become ALTR’s next Chief Executive Officer. As a Co-founder, James was key to identifying the data security hole ALTR could fill. As CTO, he has been the technical leader who envisioned how ALTR could best meet our customers’ needs and one of the most public faces of the company.
James is excited to chart the course for ALTR’s future, maintaining the company’s trajectory by ensuring we continue to anticipate, act proactively, and deliver the disruptive data governance and security solutions our customers and the market didn’t even realize were possible. We to believe that ALTR’s short “time-to-value" in a market that is fraught with complexity will deliver sustaining differentiation in the coming years.
And we’re a team here at ALTR so Dave isn’t going anywhere. He and James will work closely together during a transition period, and he will remain involved as a Board Director, CEO Advisor and ongoing financial Investor. Dave will also use this opportunity to expand his strategic advisory practice, mentor up-and-coming CEOs and explore other Board of Director opportunities.
Please don’t hesitate reach out to James, Dave or your Account Executive if you have any questions about the transition. And stay tuned for great things ahead…
If there’s one phrase we heard over and over again at Snowflake Summit 2022 (other than “data governance”) it was "data mesh." What is data mesh, you ask? Good question!
Data Mesh definition
Data mesh is a decentralized data architecture to make data available through distributed ownership of data. Various teams own, manage and share data as a product or service they offer to other groups inside the company or without. The idea is that distributing ownership of data (versus centralizing it in a data warehouse or data lake with a single owner, for example) makes it more easily accessible to those who need it, regardless of where the data is stored.
You can imagine why this might be a hot topic in the data ecosystem. Companies are constantly looking for ways to make more data available to more users more quickly. The data mesh conversation has continued in data ecosystem leader blogs we’ve gathered in our Q3 roundup.
VP Product Marketing and Analyst Relations at Alation, Mitesh Shah, interviews former Gartner Analyst Sanjeev Mohan in this Q&A-style blog. Mohan shares his definitions of data mesh, data fabric and the modern data stack and why they’re such hot topics at the moment. Mohan suggests the possibility that new terms (like data mesh) are actually history repeating itself, dives into what these new strategies and architectures bring to the table for data-first companies and identifies the pros and cons of centralizing or decentralizing data and metadata.
Eric Gerstner, Data Quality Principal, Collibra leverages his background as a former Chief Product Owner managing technology for digital transformation to dive into the data mesh concept. He explains that “No amount of technology can solve for good programmatics around the people and process.” He sees data mesh as a conceptual way of tying technology to people and processes and enabling an organization to improve its data governance. This article helps to shed light on the narrative of data mesh and how it fits into modern data organizations in both the immediate and further-out futures. He sees data mesh as key to linking people and processes – people that know how to interpret and organize data and the processes that drive and collect data into the organization itself.
This blog by Matillion really unpacks the concept of data mesh at a fundamental level. It’s really about bringing data out from its usual role as a supporting player and elevating it to a product in and of itself. It’s about “productizing” data and offering it to customers within and without the company. Customers have an expectation of the quality of the product and the service they are utilizing. A data mesh can help data owners meet those expectations. Furthermore, this blog explains the steps necessary to create a data mesh with Matillion. Matillion’s low-code/no-code platform is an ideal partner for individual data teams that include a mix of domain and technology expertise.
Data Mesh Architecture: ALTR's Take
We’re all about making data easier to access – for authorized people. As the data mesh architecture proliferates, companies need to ensure that all data owners across the company are enabled with the appropriate tools in place to keep their sensitive data from spreading recklessly – to meet both internal guidelines and government regulations on data privacy. A data mesh architecture really democratizes data ownership and access, and ALTR’s no-code, low up-front cost solution democratizes data governance to go hand in hand with it. Data owners from finance to operations to marketing do not need to know any code to implement data access controls on the sensitive data they’re responsible for.
Snowflake harnesses the power of the cloud to help thousands of organizations explore, share, and unlock the actual value of their data. Whether your company has ten employees or 10,000, if you’re one of Snowflake’s 4,500 customers and counting, you’re either thrilled or overwhelmed by the cloud data warehouse’s combination of out-of-the-box functionality and powerful, flexible features.
Wherever you are in your journey, though, it’s never too early or too late to think about how you’re handling Snowflake data governance and security for sensitive data like PII/PHI/PCI.
When you look at the enterprise-level security and governance capabilities Snowflake offers natively within the platform, you may wonder why you need more (see the Bonus question for this answer). And the options for Snowflake Data Governance offered by partners may sound similar, making it a challenge to know what the differences are and what you need.
With that in mind, we’ve put together the critical questions you should ask when evaluating Snowflake Data Governance options. Going through this list should reveal the best next step for your company.
1. Is the Snowflake data governance solution easy to set up and maintain? Does it use Proxy, Fake SaaS or Real SaaS?
There are several ways vendors can enable their Snowflake data governance solutions. One approach is to utilize a proxy. While proxy solutions have some advantages, they come with serious issues that make them less than ideal for cloud-based Snowflake:
Extra effort is required to make all applications go through the proxy, adding time, complexity, and costs to your implementation.
Security holes are created when applications and users can bypass the proxy to get full access to data, increasing risk and surfacing compliance issues
Platform changes may break the proxy without warning, adding unnecessary downtime and delays
On-premises proxies require you to deploy, maintain, and scale more infrastructure than you would with a pure-SaaS Cloud-native solution
SaaS is a better option for Snowflake data governance, but some providers calling themselves “SaaS” are better defined as "Managed Services." In these “Fake SaaS” solutions, vendors spin up, support and update an individual version of the software just for you. This makes it more expensive to run and maintain than true SaaS, costing you more. They can also require long maintenance windows that make the service unavailable during updates.
A proper multi-tenant SaaS-based data governance solution built for the cloud - like ALTR’s - is easier to start and maintain with Snowflake. There’s no hardware deployment or maintenance downtime required, no hardware sitting between your users and the data, no risk of a platform change breaking your integration, and no difficulty scaling your Snowflake usage. Because it’s natively integrated, there are no privacy issues or security holes. A real SaaS-based solution will also have the credentials to back it up: PCI DSS Level 1, SOC 2 Type II certification, and support for HIPAA compliance.
2. Is the Snowflake data governance solution easy to use? Does it require code to implement and manage?
Snowflake provides the foundation with native data governance features like sensitive data discovery and classification, access control and history, masking, and more with every release. But for users to take advantage of these Snowflake data governance capabilities on their own, they must be able to write SQL. That can make the features difficult, time-consuming, and costly to implement and manage at scale because data governance administration is limited to DBAs and other developers who can code.
However, the groundwork Snowflake provides allows partners to create solutions that leverage that built-in functionality but deliver an easier-to-use experience. ALTR’s solution provides native cloud integration and a user interface that doesn’t require code to get started or manage. This means your Data Governance teams or even line of business data or analytics users can take over the management of governance policies on Snowflake, freeing DBAs to focus on managing data streams and enabling data-driven insights.
3. It is a complete Snowflake data governance solution? Does it secure all of your data and reduce your risk?
This is crucial. You may look for a Snowflake Data Governance solution in response to privacy regulations, but you’ll never be truly compliant without a data security. And most "data governance" options don’t include data protection. While Snowflake offers many enterprise-level security features, there’s no defense against credentialed or privileged access threats. Once someone gets access with compromised credentials, there’s no mechanism for slowing or stopping data consumption.
Some software vendors calling themselves “data governance” only provide data discovery and classification – a data card catalog – without access control. And some other vendors require the data you want to protect to be copied into a new Snowflake database managed by the solution, leaving the raw data in the original database—ungoverned and unprotected. You may never know if anyone has accessed that data, potentially violating privacy regulations that require you to understand and document who has accessed data, even if nothing leaks outside the company.
For complete Snowflake Data Governance, you must not only be able to find and classify your data, but see data access, utilize consumption thresholds to detect anomalies and alert on them, respond to threats with real-time blocking, and tokenize critical data at rest. ALTR combines all these features into a single data governance and security platform that allows you to protect data appropriately based on data governance policies, ensure all your data is secure, and minimize your risk of data loss or theft.
4. Is the data governance solution affordable and flexible? Can you start with only what you need?
Most solutions cost $100k to $250k per year to start! These large, legacy on-premises platforms were not built for today’s scalable cloud environment. They require considerable time, resources, and money to even get started, which is an odd fit for Snowflake’s cloud-based platform, where Snowflake On-Demand gives you usage-based, per-second pricing with a month-to-month contract.
ALTR’s pricing starts at “free.” Our Free plan gives you the power to understand how your data is used, add controls around access, and limit your data risk at no cost. Our Enterprise and Enterprise Plus plans are available if you need more advanced governance controls, integration with SOAR or SIEM platforms, or increased data protection and dedicated support.
ALTR’s tiered pricing means there’s no large up-front commitment—you can start Snowflake data governance for free and expand if or when your needs change. Or stay on our free plan forever.
Bonus Question: Can't I just build a solution myself?
While a data admin can write Snowflake masking policy using SQL to leverage Snowflake's native features, what happens next? That is a one-time point fix but what about the long term and wide scale? Can others read and work with it? Do you have a QA team to eliminate errors? Can you ensure it scales correctly and can run quickly across thousands of databases? Do you have the time to integrate it with Okta or Matillion or Splunk? Do you have a roadmap that ensures it stays up to date with new private-preview Snowflake features, keeping up with your changing data and regulatory landscape, and addressing new user service needs? Basically, do you want your data team to be a software development team? You could hire 30 engineers and spend millions of dollars to build enterprise-ready Snowflake data governance software you can trust with the risky connection between users and data, but why should you when there are already cost-effective solutions from companies in the market focused on just this?
Conclusion
Companies flocking to the cloud data party, and Snowflake in particular, are faced with a dizzying array of options for Snowflake Data Governance. However similar the solutions may seem, with a little digging fundamental differences become apparent. ALTR’s solution stands out for its accessible, SaaS-based, no-code setup and management and complete Snowflake data governance and security feature set. And with its reasonable user- and data-based costs, ALTR becomes the obvious next step for Snowflake users to govern and protect their sensitive data.
Why is everyone talking about cloud data security today? The first wave of digital transformation focused on moving software workloads to SaaS-based applications in the cloud that were easy to spin up, required no new hardware or maintenance, and started with low costs that scaled with use. Today, the next generation of digital transformation is focused on moving the data itself — not just from on-premises data warehouses to the cloud but from other cloud-based applications and services into a central cloud data warehouse (CDW) like Snowflake. This consolidates valuable and often very sensitive data into a single repository with the goal of creating a single source of truth for the organization.
Cloud data securityis focused on protecting that sensitive data, regardless of where it’s located, where it’s shared or how it’s used. It uses role-based data access controls, privacy safeguards, encrypted cloud storage, and data tokenization among other tools to limit the data users can access in order to meet data security requirements, comply with privacy regulations and ensure data is secure.
3 Benefits of Cloud Data Security
Cloud data security confers powerful benefits with almost no downsides. In fact, the biggest risk of cloud data security is not doing it.
Improve business insights: When applied correctly, cloud data security enables data to be distributed securely throughout an organization, across business units and functional groups, without fear that data could be lost or stolen. That means you can share sensitive PII about customers with your finance teams, your marketing teams and even your sales teams, without worry that the data might make its way outside the company. You can gather information from various in-house and in-cloud business tools such as Salesforce or another CRM, your ERP, or your marketing automation solution into one centralized database where users can cross check and cross reference information across various data sources to uncover surprising insights.
Avoid regulatory fines: It’s not just credit card numbers or health information that companies need to worry about anymore – today, practically every company deals with sensitive, regulated data. Personally Identifiable Information (PII) is data that can be used to identify an individual such as Social Security number, date of birth or even home address. It’s regulated by GDPR in Europe and by various state regulations in the US. Although the regulatory landscape is still patchy in the US, all signs point to a federal level statute or new regulation that will lay out rules for companies across the country coming very soon. For companies that want to get ahead of the issue, making sure their cloud data security meets the most stringent requirements is the easiest path. This can help a company ensure its meeting its obligations and reduce risk of fines from any regulation.
Cultivate customer relationships: In a 2019 Pew Research Center study 81% of Americans said that the risks of data collection by companies can outweigh the benefits. This might be because 72% say they benefit very little or not at all from the data companies gather about them. A McKinsey survey showed that consumers are more likely to trust companies that only ask for information relevant to the transaction and react quickly to hacks and breaches or actively disclose incidents. These also happen to be some of the requirements of data privacy regulations – only gather the information you need and be upfront, timely and transparent about leaks. Companies can’t continue to gather data at will with no consequences – customers are awake to the risks now and demanding more accountability. This gives organizations a chance to strengthen the relationship with their customers by meeting and exceeding their expectations around privacy. If personalization creates a bond with customers, imagine how much more powerful that would be if buyers also trust you. Organizations that focus on protecting customer data privacy via a future-focused data governance program have an opportunity to take the lead in the market.
Cloud Data Security Challenges
Although cloud data security is a new area of concern, many of the biggest challenges are already well known by companies focused on keeping data safe.
Securing data in infrastructure your company doesn’t own: With so much data moving to the cloud, yesterday’s perimeter is an illusion. If you can’t lock data down behind a firewall, and guess what, you can’t, then you’re forced to trust your cloud data warehouse. These facilities are extremely secure, but they only cover part of your security needs. They don’t manage or control user data access – that’s left to you. Bad actors don’t care where the data is – in fact, cloud data warehouses that consolidate data from multiple sources into a single store make a compelling target. Regulators don’t care where data is either when it comes to responsibility for keeping it safe: it’s on the company who collects it. Larger companies in more regulated industries face very punitive fines if there’s a leak—which can lead to severe consequences for the business.
Securing data your team doesn’t own: From a security perspective, it’s difficult to protect data if you don’t know what it is or where it is. With various functional groups across companies making the leap to cloud data warehouses on their own in order to gain business insights, it’s difficult for the responsible groups such as security teams to be sure data is safe.
Stopping privileged access threats: When sensitive data is loaded to a CDW there’s often one person who doesn’t really need access, but still has it: your Snowflake admin. If your company is like Redwood Logistics, uploading sensitive financial data in order to better estimate costs, you really don’t want your admin to have access – and usually, he doesn’t either! Even if you trust your admin and you probably do, there’s no guarantee his credentials won’t get stolen and no upside to him or the business to allowing that access. This leads into our next challenge:
Stopping credentialed access threats: Even the most trustworthy employees can be phished, socially engineered or plain have their credentials stolen. Despite the training companies have done to educate users about these risks, the credentialed access threat continues to be one of the top sources of breach in the Verizon Data Breach Investigations Report, for the sixth year in a row! ALTR’s James Beecham asks year after year: “Why Haven’t We Stopped Credentialed Access Threats?” We know how – even when humans are fallible there is technology that can help.
Using data safely in Business Intelligence tools: One of the key goals to consolidating data into a centralized CDW is to enable business intelligence access. BI tools like Tableau, ThoughtSpot and Lookr depend on access to all available data in order to provide a full 360 view of the business. When the data can’t be utilized securely in these tools, it often results in security admins making the call to leave that data out of the equation, creating a broken view of the business.
Cloud Data Security Best Practices
There are a few best practices every organization should incorporate into their successful cloud data security program:
1. Keep your eye on the data - wherever it is
This shift to the cloud really requires a shift in the security mindset: from perimeter-centric to data-centric security. It means CISOs (Chief Information Security Officer) and security teams will have to stop thinking about hardware, data centers, firewalls, and instead focus on the end goal: protecting the data itself. Responsible teams need to embrace data governance and security policies around data throughout the organization and its data ecosystem. They need to understand who should have access to the data, understand how data is used, and place relevant controls and protections around data access. In fact they could start with a data observability program in order to understand what normal data usage looks like so they're better able to identify abnormal.
3. Add cloud data security checks and balances to your cloud data warehouse
To protect data (and your Database Administrator!) from the risk of sensitive data, put a neutral third party in place that can keep an eye on data access - natively integrated into to the cloud data platform yet outside the control of the platform admin. This separation of duties should make it impossible to access the data without key people being notified and can limit the amount of data revealed, even to admins. It can include features like real time alerts that notify relevant stakeholders at the company whenever the admin (or any user for that matter) tries to access the data. If none of the allowed users accessed the data, they’ll know unauthorized access has occurred within seconds. Alert formats can include text message, Slack or Teams notifications, emails, phone calls, SIEM integrations, etc. Data access rate limits that constrain the amount of de-tokenized data delivered to any user, including admins, also limit risk. While a user can request 10 million records, they may only get back 10,000 or 10 per hour. This can also trigger an alert to relevant stakeholders. These features ensure that no single user has the keys to the entire data store – no matter who they are.
4. Always assume credentials are compromised and cloud data is at risk
Knowing that the easiest and best ways to stop credentialed access threats are undermined by people being people, we’re simply better off assuming all credentials are compromised. Stolen credentials are the most dangerous if, once an account gets through the front door, it has access to the entire house including the kitchen sink. Instead of treating the network as having one front door, with one lock, require authorization to enter each room. This is actually Forrester’s “Zero Trust” security model – no single log in or identity or device is trusted enough to be given unlimited access. This is especially important as more data moves outside the traditional corporate security perimeter and into the cloud, where anyone with the right username and password can log in. While cloud vendors do deliver enterprise class security against cyber threats, credentialed access is their biggest weakness. It’s nearly impossible for a SaaS-hosted database to know if an authorized user should really have access or not. Identity access and data control are still up to the companies utilizing the cloud platform.
Key Components of Cloud Data Security Solutions
An effective cloud data security solution includes these key components:
Knowing where your data is and categorizing what data is sensitive: With data often spread throughout an organization’s technology stack, it can be challenging to even know all the various places sensitive data like social security numbers are stored. Solving this issue often starts with a data discovery and data classification solution that can find data across stores, group information into types of data and apply appropriate tags.
Controlling access to sensitive data: In today’s data-driven enterprises, data is not just used by data scientists. Everyone from marketing to sales to product teams may need or want access to sensitive data in order to make more informed business decisions but not everyone will be authorized to have access to all the data.Making sure you have the ability to grant access to some users but not others, or allow access to some roles but not others, in an efficient, scalable and secure way is one of the most important components of cloud data security.
Putting extra limits on sensitive data access: Data security doesn’t have to be either/or. With data access rate limits, users can be prohibited from gaining access to more data than they should reasonably need. This can stop bad actors with credentials from downloading the whole database by setting rate limits per user or per time period, ex: 10,000 records in 1 hour vs 1M.
Securing sensitive data with encryption or tokenization: Encryption is one cloud data security approach that is highly recommended by security professionals. However, it does have weaknesses and limitations when it comes to utilizing data in the cloud. Tokenization can enable data to be stored securely yet still be available for analysis.
Conclusion
There’s no chance of reversing the migration of data to the cloud and why would we want to? The benefits are so staggering, it’s well worth any challenges presented. As long as cloud data security is built in as a priority from the start, risks can be mitigated, and the full power and possibility of a consolidated Cloud Data Warehouse can come to fruition.
See how ALTR can help automate and scale your cloud data security in Snowflake. Get a demo!
The road to becoming one of today’s data-driven companies is full of challenges, not the least of which is finding and keeping the right people with the right skills to get you there. And it’s not always about the individual, it’s also about the team and finding the right combined characteristics that lead to success.
As part of our Expert Panel Series, we asked some experts in the modern data ecosystem what attributes a modern data team should have. Here’s what we heard…
“I have been referencing this McKinsey article for years now. ‘A two-speed IT architecture for the digital enterprise.’ The concept is an Enterprise IT organization (Data Platform / Networking, etc.) that manages mature assets / processes. The 2nd speed teams are smaller, agile and more focused. They focus on "shadow it,” for example: Marketing Analytics / Marketing Technology. They are allowed to do whatever they need to get the job done. But once things are mature, they can be transitioned into Enterprise IT. In my interpretation, functional areas have their own ‘smaller technology teams’ that have all the required skill sets to deliver on projects for the business unit sponsoring it.”
“Hire T-shaped skillsets and people who are happy to collaborate. Nothing is worse than a team of siloed individual contributors. [People with T-shaped skills] are team members who specialize in a particular area (such as Python, or data modeling, or infrastructure, etc.), but also have all-round skills, to a lesser degree, across the board. This allows for broad coverage across the team, without having to train everyone on everything to the same level, and also gives you team members that'll never say 'that's not my job', or sit there and pout when a particular ETL process didn't get written in Python this time around. They also tend to be inquisitive and curious by nature, and so are open to new ways of doing things and new technologies to move things forward, rather than painting themselves into a box and refusing to do anything other than what they know.
The opposite of a person with a T-shaped skillset is a one-trick pony. 😁”
“A modern team should have a variety of skills but the best attribute they can have is a shared vision of the overall goal of the data project. If the Marketing manager needs hourly reports and the data engineering team is building daily extracts there is a disconnect. The data exec level would be great, but not a necessity. Just need to do a little planning to succeed rather than rebuild everything.”
“Similar to a full-stack developer, or a ‘feature team’ for software development, having team members that are cross functional is key to accelerating your data initiatives. I have seen too many projects stall because one person says, ‘I don’t know anything about the data pipeline, so I cannot tell you the answer’ or ‘I don’t have access to the data so I cannot verify that classification report.’ These types of bottlenecks always pop up at the worst time and cause delays. Cross training team members, having folks who are not afraid of using every tool you have in your stack is critical to your success.”
You may be familiar with the idea of encryption to protect sensitive data, but maybe the idea of tokenization is new. What is data tokenization? In the realm of data security, “tokenization” is the practice of replacing a piece of sensitive or regulated data (like PII or a credit card number) with a non-sensitive counterpart, called a token, that has no inherent value. The token maps back to the sensitive data through an external data tokenization system. Data can be tokenized and de-tokenized as often as needed with approved access to the tokenization system.
How Does Tokenization of Data Work?
Original data is mapped to a token using methods that make the token impractical or impossible to restore without access to the data tokenization system. Since there is no relationship between the original data and the token, there is no standard key that can unlock or reverse lists of tokenized data. The only way to undo tokenization of data is via the system that tokenized it. This requires the tokenization system to be secured and validated using the highest security levels for sensitive data protection, secure storage, audit, authentication and authorization. The tokenization system is the only vehicle for providing data processing applications with the authority and interfaces to request tokens or de-tokenize to the original sensitive data.
Replacing original data with tokens in data processing systems and applications like business intelligence tools minimizes exposure of sensitive data in those applications, stores, people and processes, reducing risk of compromise, breach or unauthorized access to sensitive or regulated data. Applications, except for a handful of necessary applications or users authorized to de-tokenize when strictly necessary for a required business purpose, can operate using tokens instead of live data,. Data tokenization systems may be operated within a secure isolated segment of the in-house data center, or as a service from a secure service provider.
What is Data Tokenization Used For?
Tokenization may be used to safeguard sensitive data including bank accounts, financial statements, medical records, criminal records, driver's licenses, loan applications, stock trades, voter registrations, and other types of personally identifiable information (PII). Data tokenization is most often used in credit card processing, and the PCI Council defines tokenization as "a process by which the primary account number (PAN) is replaced with a surrogate value called a token. De-tokenization is the reverse process of redeeming a token for its associated PAN value. The security of an individual token relies predominantly on the infeasibility of determining the original PAN knowing only the surrogate value".
The choice of tokenization as an alternative to other data security techniques such as encryption, anonymization, or hashing will depend on varying regulatory requirements, interpretation, and acceptance by auditing or assessment entities. We cover the advantages and disadvantages of tokenization versus other data security solutions below.
Benefits of Data Tokenization
When it comes to solving these cloud migration challenges, tokenization of data has all the obfuscation benefits of encryption, hashing, and anonymization, while providing much greater usability. Let’s look at the advantages in more detail.
No formula or key: Tokenization replaces plain-text data with an unrelated token that has no value if breached. There’s no mathematical formula or key; a token vault holds the real data secure.
Acts just like real data: Users and applications can treat tokens the same as real data and perform high-level analysis it, without opening up the door to risk of leaks or loss. Anonymized data on the other hand provides only limited analytics capability because you’re working with ranges, while hashed and encrypted data are ineligible for analytics. With the right tokenization solution, you can share tokenized data from the data warehouse with any application, without requiring data to be unencrypted and inadvertently exposing it to users.
Granular analytics: Retaining the connection to the original data enables you to dig deeper into the data with more granular analytics than anonymization. Anonymized data is limited by the original parameters, such as age ranges or broad locations, which might not provide enough details or flexibility for future purposes. With tokenized data, analysts can create fresh segments of data as needed, down to the original, individual street address, age or health information.
Analytics plus protection: Tokenization delivers the advantages of analytics with the strong at-rest protection of encryption. For the strongest possible security, look for solutions that limit the amount of tokenized data that can be de-tokenization and also issue notifications and alerts when data is de-tokenized so you can ensure only approved users get the data.
Tokenization Vs. Encryption
1. Tokens have no mathematical relationship to the original data, which means unlike encrypted data, tokenized data can’t be broken or returned to their original form.
While many of us might think encryption is one of the strongest ways to protect stored data, it has a few weaknesses, including this big one: the encrypted information is simply a version of the original plain text data, scrambled by math. If a hacker gets their hands on a set of encrypted data and the key, they essentially have the source data. That means breaches of sensitive PII, even of encrypted data, require reporting under state data privacy laws. Tokenizing data, on the other hand, replaces the plain text data with a completely unrelated “token” that has no value if breached. Unlike encryption, there is no mathematical formula or “key” to unlocking the data – the real data remains secure in a token vault.
2. Tokens can be made to match the relationships and distinctness of the original data so that meta-analysis can be performed on tokenized data.
When one of the main goals of moving data to the cloud is to make it available for analytics, tokenizing the data delivers a distinct advantage: actions such as counts of new users, lookups of users in specific locations, and joins of data for the same user from multiple systems can be done on the secure, tokenized data. Analysts can gain insight and find high-level trends without requiring access to the plain text sensitive data. Standard encrypted data, on the other hand, must be decrypted to operate on, and once the data is decrypted there’s no guarantee it will be deleted and not be forgotten, unsecured, in the user’s download folder. As companies seek to comply with data privacy regulations, demonstrating to auditors that access to raw PII is as limited as possible is also a huge bonus. Data tokenization allows you to feed tokenized data directly from Snowflake into whatever application needs it, without requiring data to be unencrypted and potentially inadvertently exposed to privileged users.
3. Tokens maintain a connection to the original data, so analysis can be drilled down to the individual as needed.
Anonymized data is a security alternative that removes the personally identifiable information by grouping data into ranges. It can keep sensitive data safe while still allowing for high-level analysis. For example, you may group customers by age range or general location, removing the specific birth date or address. Analysts can derive some insights from this, but if they wish to change the cut or focus in, for example looking at users aged 20 to 25 versus 20 to 30, there’s no ability to do so. Anonymized data is limited by the original parameters which might not provide enough granularity or flexibility. And once the data has been analyzed, if a user wants to send a marketing offer to the group of customers, they can’t, because there’s no relationship to the original, individual PII.
Three Risk-based Models for Tokenizing Data in the Cloud
Depending on the sensitivity level of your data or comfort with risk there are several spots at which you could tokenize data on its journey to the cloud. We see three main models - the best choice for your company will depend on the risks you’re facing:
Level 1: Tokenize data before it goes into a cloud data warehouse
The first issue might be that you’re consolidating sensitive data from multiple databases. While having that data in one place makes it easier for authorized users, it might also make it easier for unauthorized users! Moving from multiple source databases or applications with their own siloed and segmented security and log in requirements to one central repository gives bad actors, hackers or disgruntled employees just one location to sneak into to have access to all your sensitive data. It creates a much bigger target and bigger risk.
And this leads to the second issue: as more and more data is stored in high-profile cloud data warehouses, they have become a bigger focus for bad actors and nation states. Why should they go after Salesforce or Workday or other discrete applications separately when all the same data can be found in one giant hoard?
The third concern might be about privileged accessfrom Snowflake employees or your own Snowflake admins who could, but really shouldn’t, have access to the sensitive data in your cloud data warehouse.
If your company is facing any of these situations, it makes sense for you to choose “Level 1 Tokenization”: tokenize data just before it goes into the cloud. By tokenizing data that is stored in the cloud data warehouse, you ensure that only the people you authorize have access to the original, sensitive data.
Level 2: Tokenize data before moving it through the ETL process
As you’re mapping out your path to the cloud, you may want to make sure data is protected as soon as it leaves the secure walls of your datacenter. This is especially challenging for CISOs who’ve spent years hardening the security of perimeter only to have control wrested away as sensitive data is moved to cloud data warehouses they don’t control. If you’re working with an outside ETL (extract, transform, load) provider to help you prepare, combine, and move your data, that will be the first step outside your perimeter you want to safeguard. Even though you hired them, without years of built-up trust, you may not want them to have access to sensitive data. Or it may even be out of your hands—you may have agreements or contracts with your own customers that specify you can’t let any vendor or other entity have access without written consent.
In this case, “Level 2 Tokenization” is probably the right choice. This takes one step back in the data transfer path and tokenizes sensitive data before it even reaches the ETL. Instead of direct connection to the source database, the ETL provider connects through the data tokenization software which returns tokens. ALTR partners with SaaS-based ETL providers like Matillion to make this seamless for data teams.
Level 3: End-to-end on-premises-to-cloud data tokenization
If you’re a very large financial institution classified as “critical vendor” by the US government, you’re familiar with the arduous security required. This includes ensuring that ultra-sensitive financial data is exceedingly secure – no unauthorized users, inside or outside the enterprise, can have access to that data, no matter where it is. You already have this nailed down in your on-premises data stores, but we’re living in the 21st century and everyone from marketing to IT operations is saying “you have to go to the cloud.” In this case, you’ll need “Level 3 Tokenization”: full end-to-end data tokenization from all your onsite databases through to your cloud data warehouse.
As you can imagine, this can be a complex task. It requires tokenization of data across multiple on-premises systems before even starting the data transfer journey. The upside is that it can also shine a light on who’s accessing your data, wherever it is. You’ll quickly hear from people throughout the company who relied on sensitive data to do their jobs when the next time they run a report all they get back is tokens. This turns into a benefit by stopping “dark access” to sensitive data.
Conclusion
Data tokenization can provide unique data security benefits across your entire path to the cloud. ALTR’s SaaS-based approach to data tokenization-as-a-service means we can cover data wherever it’s located: on-premises, in the cloud or even in other SaaS-based software. This also allows us to deliver innovations like new token formats or new security features more quickly, with no need for users to upgrade. Our tokenization solutions also range from flexible and scalable vaulted tokenization all the way up to PCI Level 1 compliant, allowing companies to choose the best balance of speed, security, and cost for their business. We’ve also invested heavily in IP that enables our database driver to connect transparently and keep data usable while tokenized. The drivers can, for example, perform the lookups and joins needed to keep applications that are unused to tokenization running.
With data tokenization from ALTR, users can bring sensitive data safely into the cloud to get full analytic value from it, while helping meet contractual security requirements or the steepest regulatory challenges.




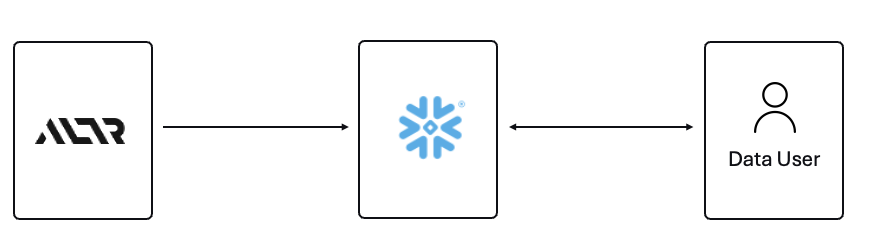










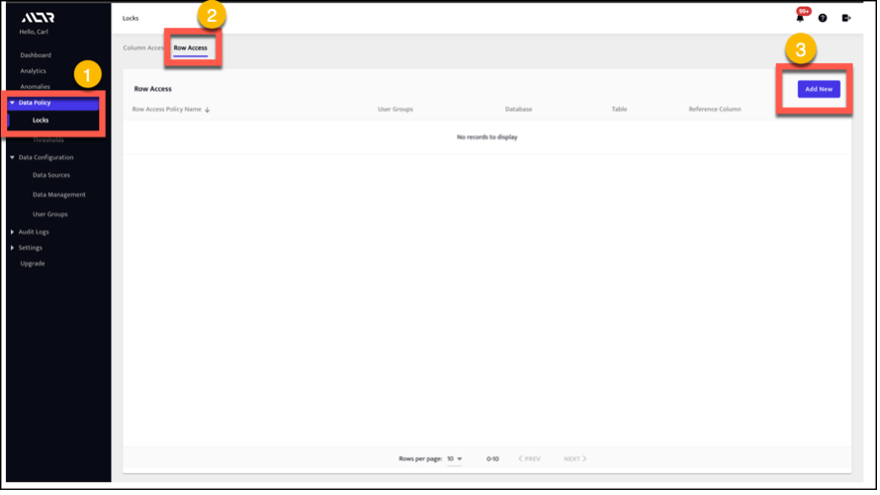
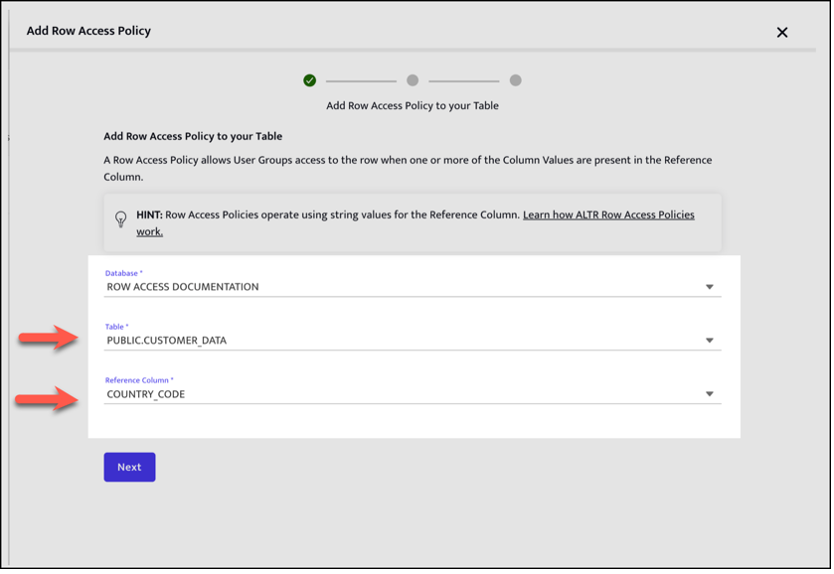

.png)