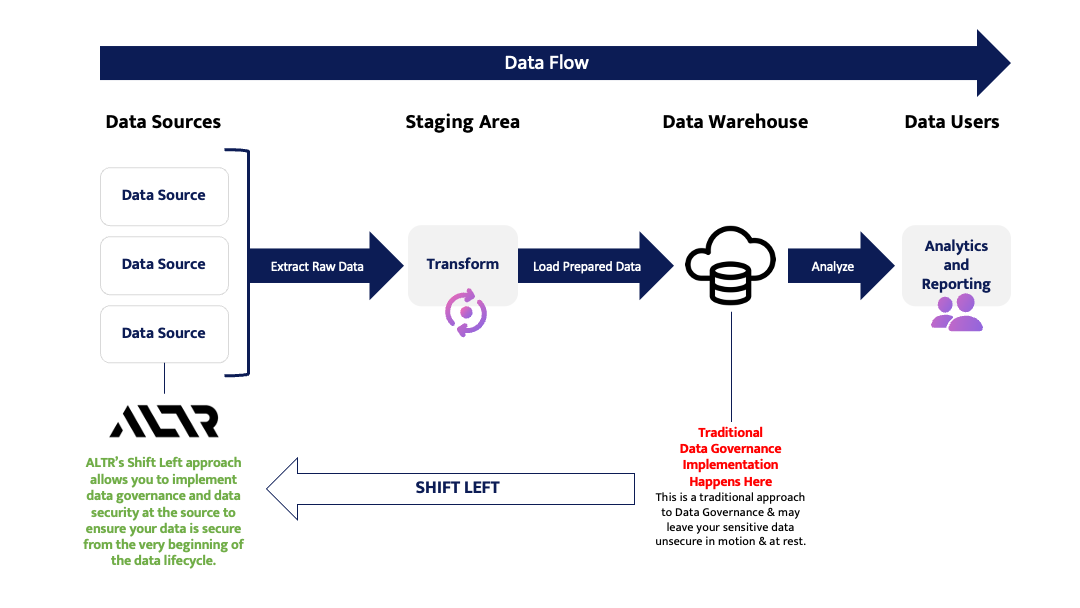
Data is the new oil fueling industry transformations, innovations, and revolutions. However, just as oil can cause environmental hazards if mishandled, poorly managed data can lead to catastrophic consequences for organizations. The imperative question is not if but when organizations should start implementing data governance and security. The straightforward answer is now, and this article delves into the compelling reasons behind this urgency.
The Increasing Value and Vulnerability of Data
In the past decade, data has transcended its role from being a mere byproduct of business activities to a core asset. The rise of big data analytics, artificial intelligence, and machine learning has exponentially increased the value derived from data. However, with great value comes great vulnerability. The more integral data becomes to business operations, the more attractive it becomes to malicious entities.
The Ever-Evolving Regulatory Landscape
The regulatory landscape regarding data privacy and security is constantly evolving. Regulations like the General Data Protection Regulation (GDPR) in Europe and the California Consumer Privacy Act (CCPA) in the United States have set new precedents in data protection. These regulations don't just demand compliance; they necessitate a proactive approach to data governance. Non-compliance can result in hefty fines, but beyond that, it can severely damage an organization's reputation.
The High Cost of Data Breaches
Data breaches are no longer rare occurrences but a looming threat. The cost of a data breach is not just financial; it encompasses legal repercussions, loss of customer trust, and long-term brand damage. IBM's Cost of a Data Breach Report highlights the escalating costs and impacts of data breaches. This reality underscores the need for robust data governance and security measures as foundational, not just add-on, business strategies.
Early Implementation: A Strategic Advantage
Implementing data governance and security early offers a strategic advantage. It's easier and more cost-effective to embed these practices into the organizational fabric from the start rather than retrofitting them later. Early implementation allows organizations to build a culture of data responsibility, where data is handled with the care and strategic insight it deserves.
The Role of Data in Decision-Making
Data-driven decision-making is the cornerstone of modern businesses. The integrity and reliability of data are paramount in this process. Without strong governance and security, data can be corrupted, leading to misguided decisions that could have far-reaching negative consequences.
Data Security as Customer Trust Builder
In an era where customers are increasingly aware and concerned about their data privacy, robust data governance and security can become a unique selling proposition. Demonstrating a commitment to data security can build customer trust and loyalty, which are invaluable assets in the competitive business landscape.
The Technological Imperative
Technology evolves at a breakneck pace, as do the methods to compromise it. Organizations that delay implementing data governance and security are in a perpetual game of catch-up, vulnerable to the latest threats. An early start in adopting these practices means staying ahead in this technological race.
The Human Factor
Data breaches are not always a result of sophisticated cyber-attacks; often, they stem from human error. Early implementation of data governance and security involves training and creating employee awareness, which is crucial in mitigating these risks.
The Competitive Edge
How an organization manages its data can become a competitive advantage in the data economy. Companies that excel in data governance and security are more agile, make better decisions, and are trusted more by customers and partners. This trust translates into tangible business outcomes.
Future-proofing the Business
The future is data-centric, and the businesses that thrive will be those that have mastered the art of managing and protecting their data. Implementing data governance and security is not just about addressing current needs; it's about future-proofing the business in a world where data will only grow in importance.
How to Get Started with Data Governance & Security
Embarking on the data governance and security journey can seem daunting, but it is essential and manageable with the right approach. Here are practical tips to help organizations get started:
Assess Your Organization’s Readiness
Evaluating your organization's current state is crucial before embarking on a data governance and security journey. This assessment involves reviewing existing data management practices, understanding the data lifecycle within your organization, and identifying the key stakeholders. Evaluate the technology infrastructure and its capacity to support data governance initiatives. Understand the level of data literacy among employees and identify the gaps in skills and knowledge that need to be addressed. This readiness assessment lays the groundwork for a successful data governance program by highlighting areas that require immediate attention and improvement.
Define Data Governance Objectives and Scope
The next step is clearly articulating what you aim to achieve through data governance. Objectives can range from ensuring regulatory compliance and improving data quality to enabling better decision-making. Once objectives are set, define the scope of your data governance program. Decide which data assets will be governed, who will be involved, and the boundaries of the initiative. This step ensures that the data governance and security program is aligned with the organization's strategic goals and has a clear direction.
Establish a Data Governance Framework
Creating a robust data governance framework is vital. This framework should encompass policies, standards, procedures, and data management guidelines. It also involves defining roles and responsibilities around data, such as data owners, stewards, and custodians. The framework should be flexible yet comprehensive, accommodating changes in business strategies, technologies, and regulations. Effective governance frameworks are often iterative, evolving as the organization grows and learns.
Implement Data Quality Management
High data quality is essential for reliable analytics and decision-making. Start by defining data quality for your organization, including accuracy, completeness, consistency, and timeliness. Develop processes for ongoing data quality assessment, including data cleansing, validation, and remediation methods. Establishing a mechanism for continuous data quality monitoring and improvement is also essential. This ongoing commitment to maintaining high data quality is a cornerstone of effective data governance.
Establish Data Security and Privacy Controls
Establishing robust data security and privacy controls is non-negotiable in the era of increasing cyber threats and stringent data protection laws. This involves deploying technological solutions like access controls and tokenization and formulating policies and procedures that ensure data is handled securely and ethically. Regular training and employee awareness programs about data security best practices are also crucial. Ensuring compliance with relevant data protection laws like GDPR or CCPA should be integral to your data governance program.
Define Data Governance Metrics
To measure the effectiveness of your data governance program, it's essential to define relevant metrics and KPIs. These could include data quality measures, compliance levels, the efficiency of data management processes, or the impact of data governance on decision-making. Regularly tracking these metrics will help assess the program's performance and identify areas for improvement. It also helps demonstrate the value of data governance to stakeholders and secure ongoing support.
Continuously Evolve and Improve
Data governance is not a one-time project but a continuous journey. As your organization evolves, so should your data governance program. This means regularly revisiting and revising the governance framework, staying updated with emerging technologies, cybersecurity threats and regulatory changes, and continually seeking stakeholder feedback. Foster a culture of continuous improvement where learning and adapting are part of the organization's approach to data governance.
Wrapping Up
The question of when to implement data governance and data security has a simple yet profound answer: the time is now. In an increasingly data-driven world, these practices are not just safeguards but fundamental to sustainable business growth and success. Organizations that recognize and act on this imperative will navigate the future with confidence and resilience, turning their data into a wellspring of opportunities rather than a source of constant threats. Therefore, the call to action is clear and immediate: prioritize data governance and security today, for it is the cornerstone upon which the successful organizations of tomorrow will be built.