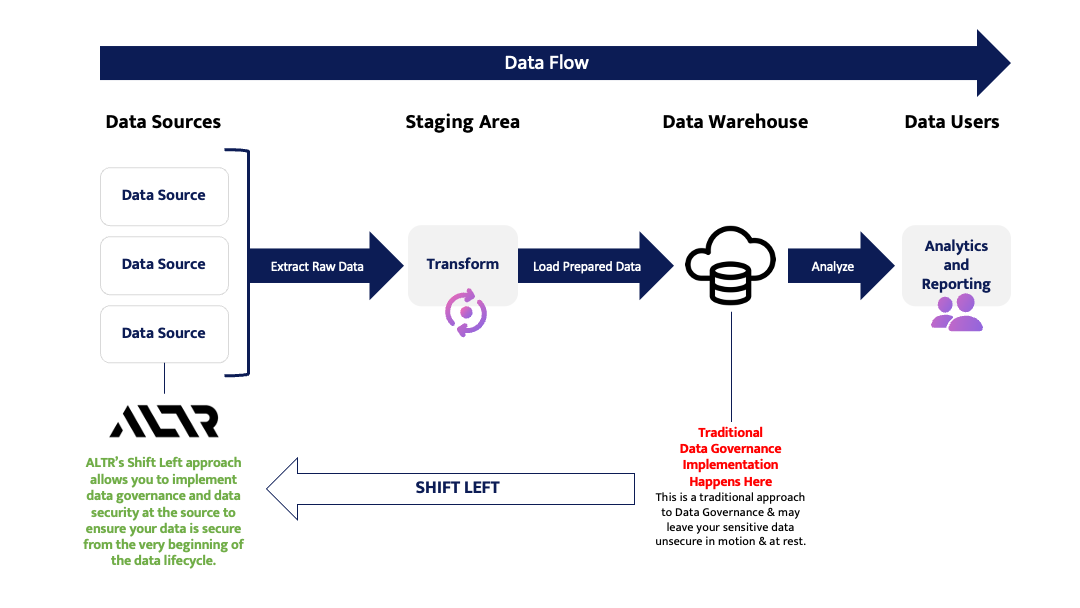
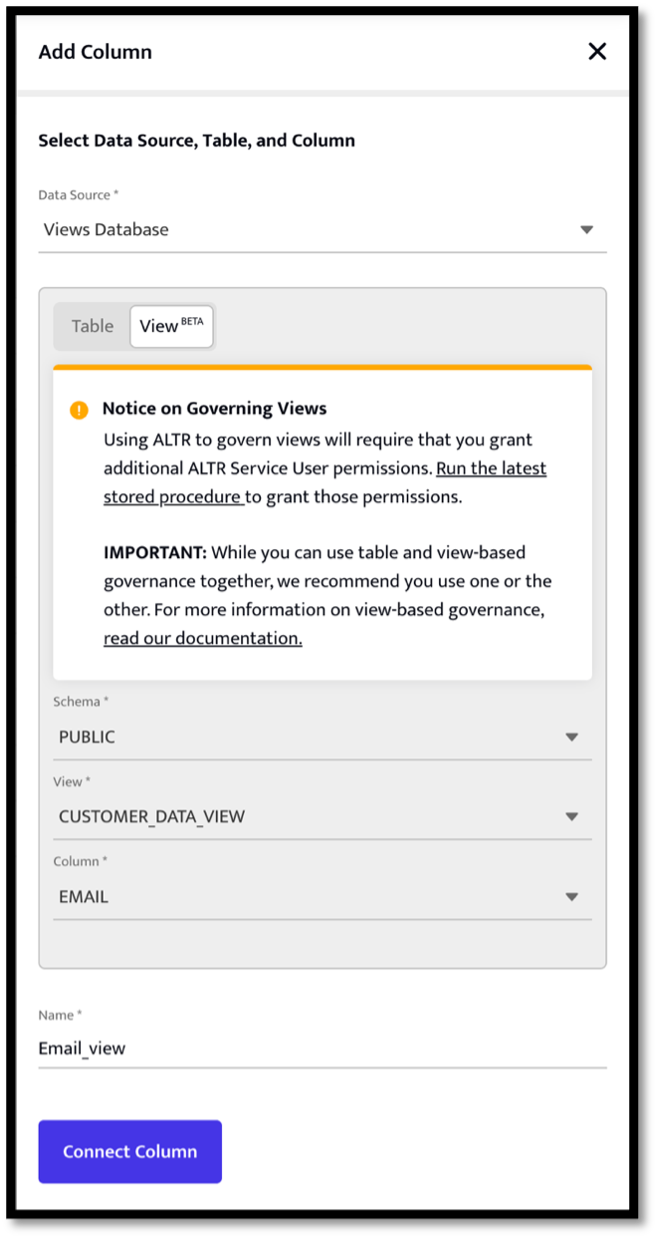
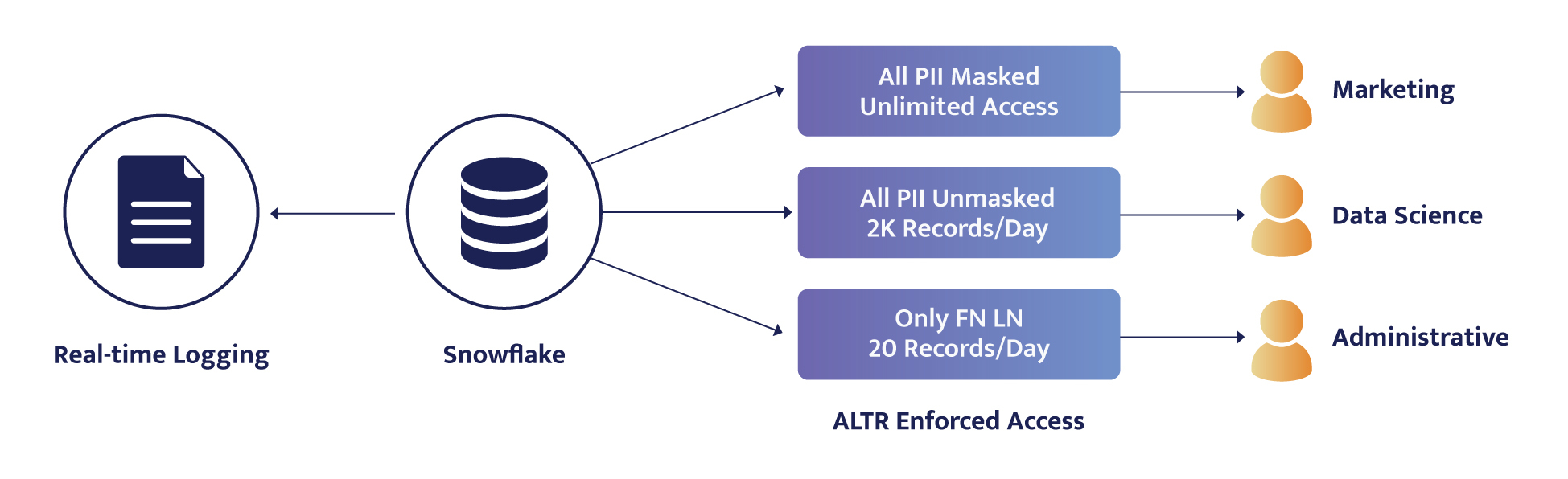
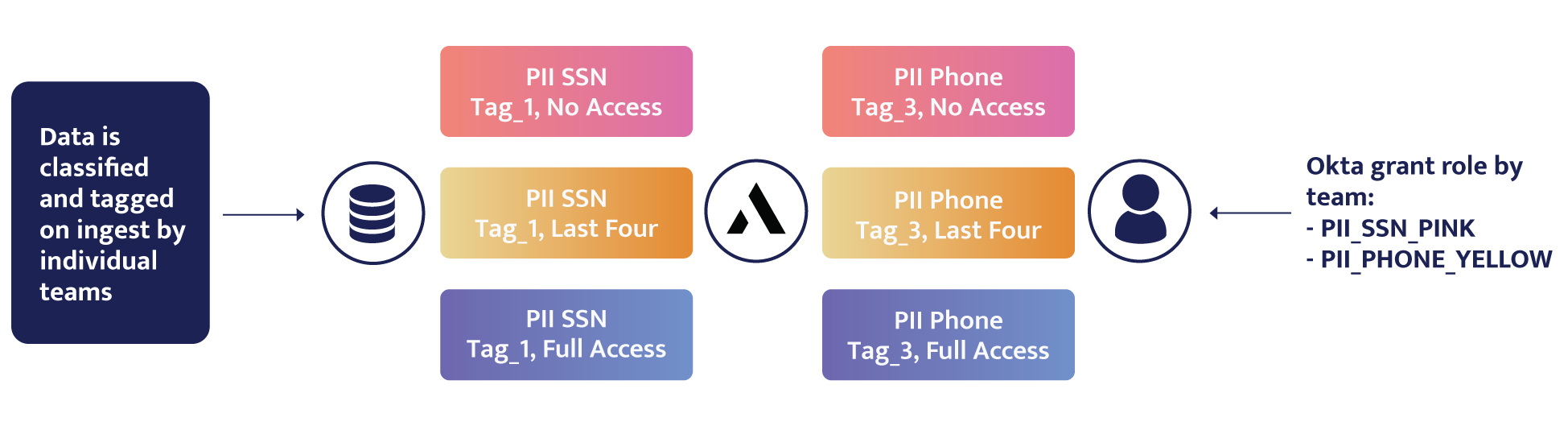
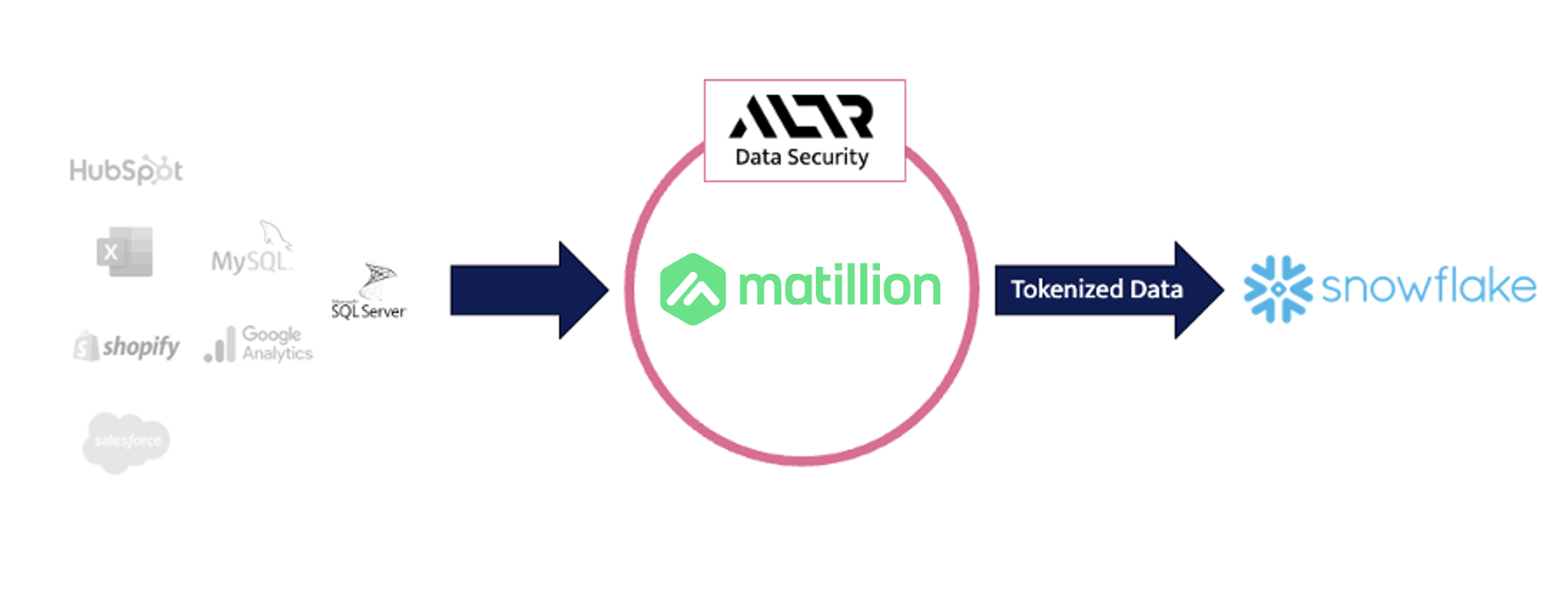
In the realm of modern enterprises, safeguarding sensitive data is paramount. Data breaches and regulatory compliance challenges loom large, demanding robust solutions. Fear not, for data masking emerges as the agile and versatile knight in shining armor, equipping organizations with the power to shield their precious data assets while maintaining usability and compliance.
This guide delves into the dynamic world of data masking, exploring the factors driving its adoption, the different types of masking available and critical technique selection considerations for successful implementation.
But First, What is Data Masking?
Data masking is a data protection technique involving transforming or obfuscating sensitive information within an organization's databases or systems. It aims to conceal or alter the original data to render it unreadable while maintaining its functional and logical integrity.
By replacing sensitive data with fictitious or anonymized values, data masking safeguards individuals' privacy, mitigates the risk of unauthorized access or data breaches and ensures compliance with data protection regulations. This process enables you to maintain data usability for various purposes, such as testing, development, analytics, and collaboration, while minimizing the exposure of sensitive information.
Why is Data Masking Important?
Compliance with Data Protection Regulations
Companies are often required to comply with data protection regulations such as the General Data Protection Regulation (GDPR), Health Insurance Portability and Accountability Act (HIPAA), and Payment Card Industry Data Security Standard (PCI DSS). Data masking helps you meet these regulatory requirements by protecting sensitive data and ensuring privacy.
Safeguarding Sensitive Information
Companies possess a vast amount of sensitive data, including personally identifiable information (PII), personal health information (PHI), financial records like credit card numbers (PCI), intellectual property, and trade secrets. Data masking allows you to protect this information from internal and external unauthorized access. By masking sensitive data, you can limit exposure and prevent data breaches.
Mitigating Insider Threats
Insider threats are a significant concern for companies. Employees, contractors, or partners with legitimate access to sensitive data may intentionally or accidentally misuse or disclose it. Data masking restricts the visibility of sensitive data, ensuring that only authorized individuals can view authentic information. This reduces the risk of insider threats and unauthorized data leaks.
Minimizing Data Breach Risks
Data breaches can lead to significant financial and reputational damage for companies. By masking sensitive data, the stolen or leaked data will be useless or significantly less valuable to attackers, even if a breach occurs. Masked data does not reveal original values, reducing the impact of a violation and protecting the privacy of individuals.
Creating Secure Non-Production Environments
Companies often use non-production environments for development, testing, or training purposes. These environments may contain sensitive data copies from production systems. Data masking ensures that sensitive information is replaced with realistic but fictional data, eliminating the risk of exposing real customer or employee information in non-production environments.
Enabling Data Sharing and Collaboration
Data masking allows you to securely share sensitive data with third parties, partners, or researchers. By masking the data, you can maintain privacy while still allowing data analysis, research, or collaborative efforts without compromising the confidentiality of the information.
Preserving Data Utility
Data masking techniques aim to balance data privacy and data utility. Companies must ensure that masked data remains usable for various purposes, including application development, testing, data analytics, and reporting. You can protect data using appropriate masking techniques while retaining its value and usefulness.
Types of Data that Require Data Masking
Various types of data can benefit from data masking to ensure privacy and security including:
- Personally Identifiable Information (PII): This includes names, addresses, social security numbers, passport numbers, and driver's license numbers.
- Financial Data: Credit card numbers (or PCI), bank account details, and financial transaction records are sensitive data that warrant data masking.
- Healthcare Information: Protected Health Information (PHI) like medical records, patient diagnoses, treatment details, and health insurance information must be masked to comply with regulations like HIPAA.
- Human Resources (HR) Data: Employee records, salary information, and employee identification numbers may require data masking to protect privacy and prevent identity theft.
- Customer Data: Customer names, contact information, purchase history, and loyalty program details should be masked to safeguard customer privacy.
- Intellectual Property: Trade secrets, patents, research and development data, and proprietary information should be masked to prevent unauthorized access and maintain competitiveness.
Types of Data Masking
Static Data Masking
Static data masking permanently replaces sensitive data with fictitious or anonymized values in non-production environments. It aims to provide realistic but de-identified data that can be used for testing, development, training, or sharing purposes while preserving privacy and security.
Static data masking typically operates on a copy of the original dataset, where sensitive information, such as personally identifiable information (PII) or financial details, is masked with fictional equivalents. This process ensures that the masked data retains the same structure, format, and relationships as the original data while rendering the sensitive information unreadable and meaningless to unauthorized individuals.
Dynamic Data Masking
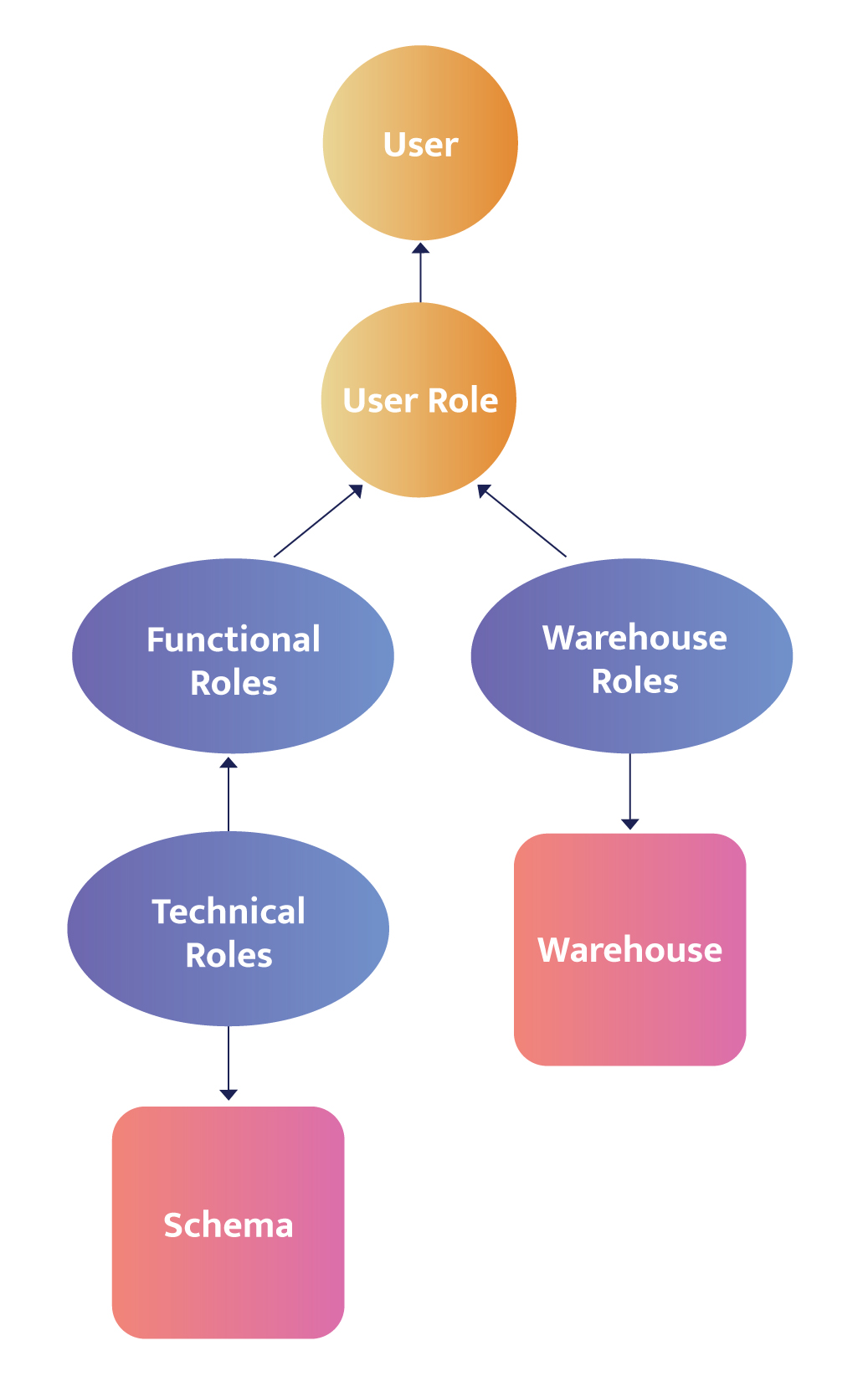
Dynamic data masking allows real-time masking of sensitive data at the point of access based on user roles and permissions. With dynamic data masking, the sensitive data remains stored in its original form. Still, it is dynamically masked or obfuscated when queried or accessed by users who do not have the necessary privileges.
This technique provides fine-grained control over data exposure, ensuring that individuals only see the masked data they are authorized to access. Dynamic data masking helps prevent unauthorized users from viewing or accessing sensitive information while allowing authorized users to interact with the data in its unmasked form.
Deterministic Data Masking
Deterministic data masking is a data protection technique where sensitive data is consistently transformed into the same masked output value using a predefined algorithm or function. Unlike other masking methods that introduce randomness or variability, deterministic data masking ensures that the same input value will always result in the same masked value.
This approach is instrumental when data relationships, referential integrity, or consistency must be maintained across different systems or environments. However, it is essential to consider potential privacy and security risks associated with deterministic data masking, as the consistent masking pattern could potentially be exploited through reverse engineering or pattern recognition techniques, necessitating additional safeguards to protect sensitive information.
Data Masking Techniques
When we use the term “data masking” by default we’re often referring to the practice of replacing some numbers in a string with asterisks – such as an email address like ****@altr.com. However, data masking can actually refer to a wide range of techniques for obfuscating and anonymizing data. Here are a few data masking techniques.
Format-Preserving Encryption
Format Preserving Encryption (FPE) allows data to be encrypted while retaining its original format, such as length or data type. It ensures compatibility with existing systems and processes, making it useful for protecting sensitive data without extensive modifications. FPE can be deterministic or randomized, providing consistent or variable ciphertext for the same input. It is commonly used when preserving data format is crucial, such as encrypting credit card numbers or identification codes while maintaining their structure.
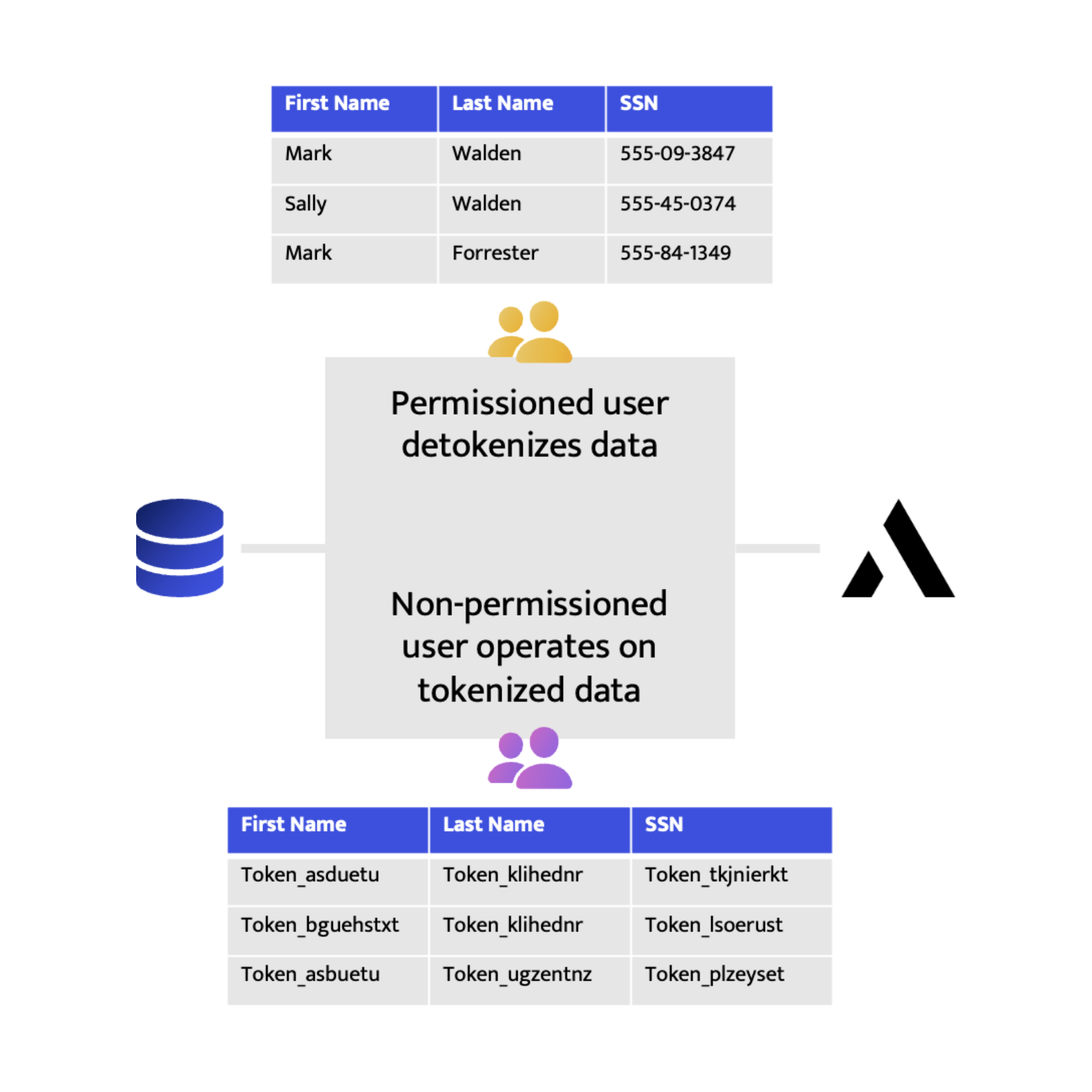
Data Tokenization
Data tokenization replaces sensitive data with unique tokens or surrogate values. Unlike encryption, where data is transformed into ciphertext, tokenization generates a token with no mathematical relationship to the original data. The token serves as a reference or placeholder for the sensitive information, while the actual data is securely stored in a separate location called a token vault. Tokenization ensures that sensitive data is never exposed, even within the organization's systems or databases.
Data Scrambling
Scrambling involves shuffling or rearranging the characters or values within a data field, rendering it unreadable without affecting its overall structure. This technique is commonly used for preserving data integrity while masking sensitive information.
For example, consider a dataset containing employee salary information. With data scrambling, the original values within the "Salary" field are shuffled or rearranged in random order. For instance, an employee with a salary of $50,000 might be masked as $80,000, while another employee's salary of $75,000 could become $35,000. The resulting scrambled values retain the structure of the data but make it challenging to associate specific salaries with individuals.
Data Substitution
Substitution replaces sensitive data with fictitious values, ensuring that the overall format and characteristics of the data remain intact. Examples include replacing names, addresses, or phone numbers with random or fictional counterparts.
Data Shuffling
Data Shuffling rearranges sensitive information randomly, breaking the relationship between values while preserving data structure. For example, imagine a dataset containing customer information, including names and addresses. With data shuffling, the original values within each field are scrambled, resulting in a randomized order. For instance, the name "John Smith" might become "Smith John," and the address "123 Main Street" could transform into "Street Main 123."
Value Variance
Value variance adds an element of unpredictability to the masking process. It ensures that the resulting masked value varies across instances even when the same original value is encountered. For example, a social security number "123-45-6789" might be masked as "XXX-XX-XXXX" in one instance and "555-55-5555" in another. By introducing this variability, value variance thwarts attempts to correlate masked data, making it significantly more challenging for unauthorized individuals to uncover sensitive information.
Nulling Out
Nulling out replaces sensitive information with null or empty values, removing any trace of the original data. This technique is beneficial when sensitive information is not required for specific use cases, such as non-production environments or scenarios where privacy is a top concern. Nulling out eliminates sensitive data, minimizing the risk of accidental exposure or unauthorized access.
Pseudonymization
Pseudonymization replaces sensitive data with pseudonyms or surrogate values. The pseudonyms used in the process are typically unique and unrelated to the original data, making it challenging to link the pseudonymized data back to the original individuals or sensitive information.
For example, healthcare data might contain a patient's name, "John Smith," address, "123 Main Street," and medical record, "PatientID: 56789." Through pseudonymization, the organization replaces these values with unique and unrelated pseudonyms. For instance, the patient's name could be pseudonymized as "Pseudonym1," the address as "Pseudonym2," and the medical record as "Pseudonym3." These pseudonyms are consistent for a particular individual across different records but are not directly linked to their original data.
How to Determine Which Data Masking Technique is Right for You
When determining which data masking technique to apply, several factors should be considered:
Data Sensitivity
First things first, you must understand the sensitivity of the data being masked. Identify the specific data elements that need protection, such as personally identifiable information (PII), financial data, or healthcare records. This assessment helps determine the level of masking required and guides the selection of appropriate techniques.
Regulatory and Compliance Requirements
Consider the relevant data protection regulations and compliance standards that govern the data. Different regulations may have specific requirements for data masking or anonymization. Ensure that the chosen technique aligns with the regulatory obligations applicable to the data.
Data Usage and Usability
Evaluate how the data will be used and the level of functionality required. Consider the intended application, such as testing, development, analytics, or research. The selected technique should preserve the usability and integrity of the data while protecting sensitive information.
Data Relationships and Dependencies
Assess the data relationships and dependencies within the dataset. Determine if any referential integrity constraints, foreign critical dependencies, or relational dependencies need to be maintained. The chosen technique should preserve these relationships while masking sensitive data.
Performance and Scalability
Consider the performance impact and scalability of the chosen technique. Some masking techniques may introduce additional processing overhead, impacting system performance or response times. Evaluate the system's capacity to handle the masking process effectively and efficiently, especially for large datasets or complex queries.
Security and Access Controls
Evaluate the security requirements and access controls associated with the data. Consider the level of granularity needed to control access to masked data. Some techniques, such as dynamic data masking, provide fine-grained control over data exposure based on user roles and permissions.
Data Retention and Data Lifecycle
Assess the data retention policies and the lifecycle of the data. Determine if the masked data needs to be retained for a specific period and if there are any data destruction or archival requirements. Consider how the chosen technique aligns with the data retention and lifecycle requirements.
Cost and Resources
Evaluate the cost and resource implications of implementing the chosen masking technique. Some techniques may require specialized tools or resources for implementation and maintenance. Consider the budgetary constraints and resource availability within the organization.
Wrapping Up
In a world where data is king and privacy is paramount, data masking emerges as the unsung hero in data security. It's the guardian of sensitive information, the gatekeeper against breaches, and the enabler of trust in an interconnected landscape. With a careful blend of innovation and best practices, data masking allows organizations to dance the delicate tango of privacy and usability, ensuring data remains safe while retaining its functionality.




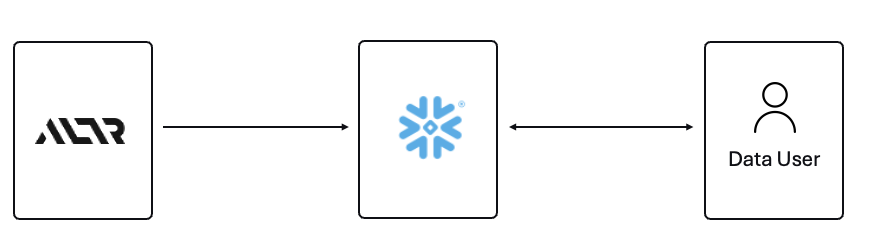











.png)